Orchestrating AI Agents for Data Pipelines
Data pipelines are the most boring part of engineering — until they break. Then they’re the most expensive.
I spent two years at Meta running Spark + Airflow pipelines that processed 10TB+ per day. The infrastructure was impressive. The failure modes were not. A single upstream schema change could silently corrupt downstream models for days before anyone noticed. A partition key format change once poisoned a week of training data. The fix took 45 minutes. The detection took six days.
That six-day gap is not an anomaly. Monte Carlo’s 2023 State of Data Quality survey found that 68% of data teams need four or more hours just to detect a pipeline failure, with an average resolution time of 15 hours per incident — and organizations average 67 incidents per month. The business impact: 31% of revenue is exposed to data quality issues, up from 26% the year prior.
This is the dirty secret of data engineering at scale: we’ve built incredibly powerful pipes and incredibly dumb monitoring. What if the pipes could think?
The Brittleness Problem
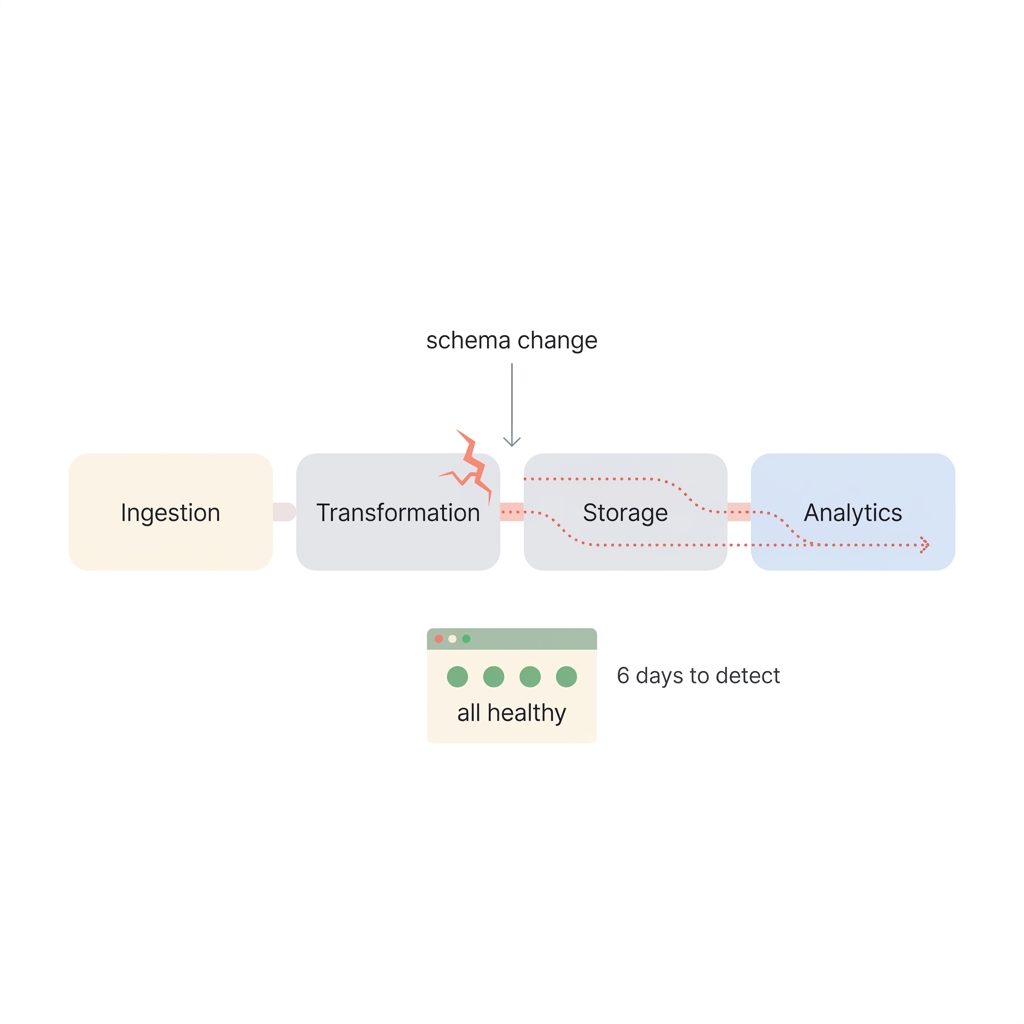
Traditional data pipelines follow a rigid choreography:
- Extract — pull from source (database, API, event stream)
- Transform — clean, reshape, enrich
- Load — write to destination (warehouse, lake, feature store)
Each step assumes the world hasn’t changed since the pipeline was written. But the world always changes. Upstream teams rename columns. API response formats evolve. Event schemas gain new fields. And your pipeline — faithfully executing the DAG you wrote six months ago — silently produces garbage.
The standard defense is testing: schema validation, data quality checks, anomaly detection. But these are reactive by design. They catch problems after the data is already wrong. At 10TB/day, even a 0.1% failure rate means 10GB of corrupted data flowing downstream before anyone raises an alarm. And the industry data confirms the pattern: Monte Carlo found a steady ratio of one data quality incident per 15 tables per year across their platform — meaning a 600-table warehouse generates roughly 40 incidents annually just from normal operations.
I call this the Detection-Resolution Gap: the growing distance between when data goes bad and when someone does something about it. Every hour in that gap compounds damage — bad dashboards inform bad decisions, corrupted features degrade ML models, and downstream consumers silently ingest poison. The gap is widening because data volumes grow faster than team headcount. You can’t hire your way out of it.
The Agent Intelligence Layer
The fix isn’t better tests. It’s a different primitive.
Instead of writing pipelines as static DAGs with bolted-on checks, design them as networks of specialized agents that observe, decide, and act at each pipeline boundary. The agents don’t replace your Spark jobs or Airflow DAGs — they sit between pipeline stages as an intelligence layer, making decisions that previously required a human on-call.
I think of this as the Observe-Decide-Act Loop — a pattern that distinguishes agent-based pipelines from traditional monitoring:
Traditional pipeline:
Source → Transform → Load → [check after the fact] → Alert human → Human investigates → Human fixes
Agent-orchestrated pipeline:
Source → [Agent: observe schema, decide compatibility] → Transform → [Agent: observe distributions, decide quality] → Load
↓ (if anomaly detected)
[Handoff to specialist agent → auto-remediate → resume]The critical shift: decisions happen inline, before bad data propagates, not after. The Detection-Resolution Gap collapses from hours to seconds.
Three Primitives That Make It Work
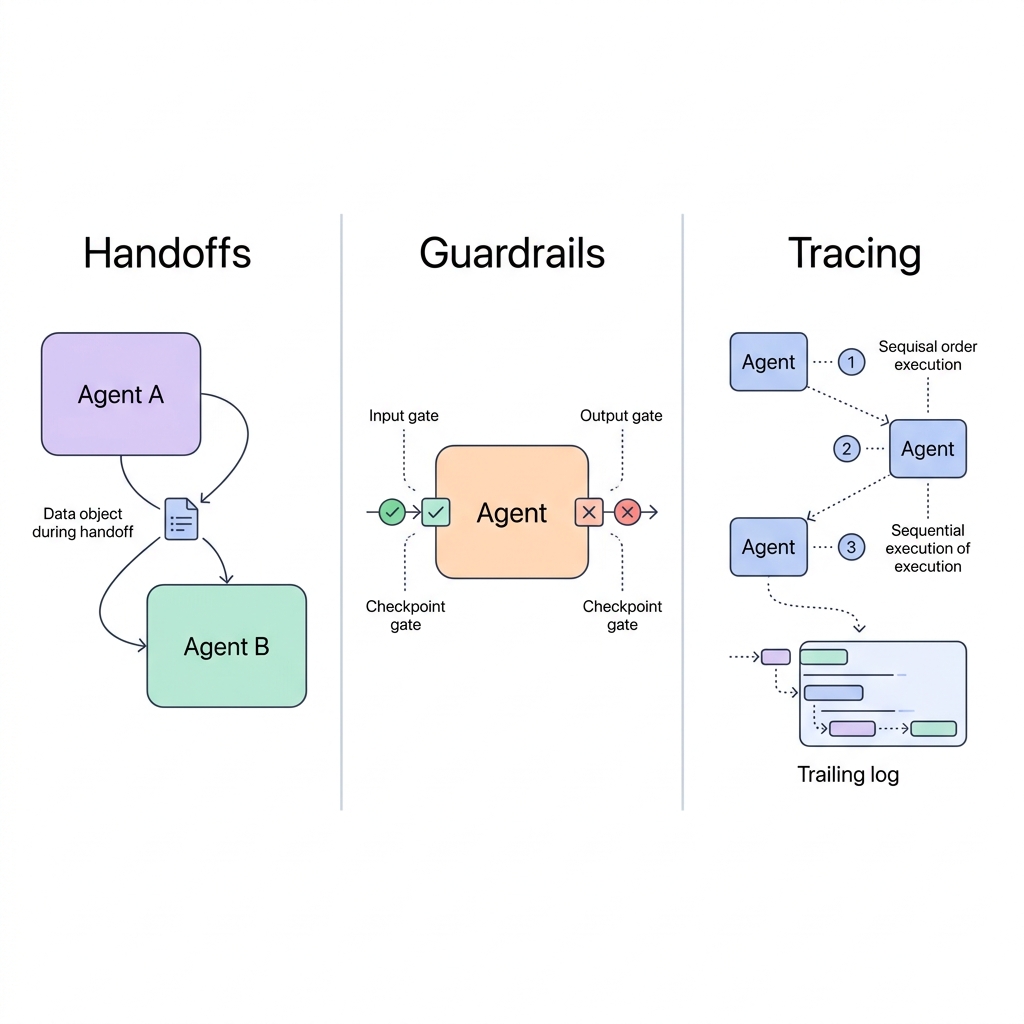
OpenAI’s Agents SDK crystallizes three primitives that map cleanly onto pipeline orchestration:
Handoffs — An agent can delegate to another agent. In pipeline terms: the ingestion agent detects a schema anomaly and hands off to a schema resolution agent, which generates the mapping transformation before passing data downstream. No human paged at 3am. No six-day detection lag. The SDK supports this through explicit handoff declarations where a triage agent routes to specialists who then own the resolution.
Guardrails — Input and output validation gates on every agent. Not just “is this field non-null?” but “does this distribution look right? Is this schema compatible with what downstream consumers expect? Did we lose cardinality during the join?” Guardrails encode the contracts between pipeline stages — making implicit assumptions explicit and enforceable.
Tracing — End-to-end observability across the entire agent network. Every decision, every handoff, every guardrail check is logged with full reasoning context. When something goes wrong, you don’t grep through Airflow logs — you replay the agent’s decision chain. This is what makes agent-based pipelines debuggable, not just automated.
These three primitives compose into what I call Contract-Aware Orchestration: each agent doesn’t just process data — it understands the contract it must uphold for downstream consumers and actively enforces it. Traditional ETL treats contracts (when they exist at all) as documentation. Agent-based pipelines treat them as runtime constraints.
A Concrete Pattern: The Schema Drift Guardian
Here’s what this looks like in practice. Consider the most common pipeline failure: an upstream team adds, renames, or removes a column, and your pipeline either crashes or silently drops data.
A Schema Drift Guardian agent handles this inline:
from agents import Agent, Runner, GuardrailFunctionOutput, input_guardrail
from pydantic import BaseModel
from typing import Literal
class SchemaVerdict(BaseModel):
status: Literal["compatible", "breaking", "additive"]
changes: list[str]
remediation_sql: str | None
confidence: float
quality_agent = Agent(
name="SchemaGuardian",
instructions="""You are a schema compatibility agent for a production data pipeline.
Given the registered schema contract and the incoming data schema:
1. Classify the change: additive (new columns), breaking (removed/renamed/retyped columns),
or compatible (no change).
2. For additive changes: generate ALTER TABLE statements to evolve the destination schema.
3. For breaking changes: generate transformation SQL that maps the new schema to the
existing contract, preserving all downstream dependencies.
4. Assign confidence (0-1). If confidence < 0.85, flag for human review instead of
auto-applying.
Never silently drop columns. Never assume a renamed column is a new column without
checking value distributions.""",
model="gpt-4o",
output_type=SchemaVerdict,
)
remediation_agent = Agent(
name="SchemaRemediator",
instructions="""You resolve schema mismatches between upstream sources and downstream
consumers. Given the SchemaGuardian's verdict:
- For additive changes: apply the evolution and notify downstream consumers.
- For breaking changes with confidence >= 0.85: apply the transformation SQL,
run validation on a sample batch, and proceed if validation passes.
- For breaking changes with confidence < 0.85: quarantine the batch, notify the
on-call engineer with full context, and continue processing other sources.
Always log the before/after schema diff and the remediation applied.""",
model="gpt-4o",
)
# The handoff: guardian escalates to remediator when schema drift is detected
quality_agent.handoffs = [remediation_agent]The key design choices here:
- Structured output (
SchemaVerdict) — the agent doesn’t produce free-form text; it returns a typed decision that downstream code can act on deterministically. - Confidence thresholds — the agent knows when it’s uncertain and escalates to a human rather than auto-applying a bad fix. This is the difference between useful automation and dangerous automation.
- Separation of detection and remediation — the guardian classifies; the remediator acts. This separation makes each agent simpler to test, debug, and improve independently.
Compare this to the traditional approach:
# Traditional: brittle, reactive, manual
try:
df = spark.read.parquet(source_path)
df_transformed = df.select(EXPECTED_COLUMNS) # crashes if columns changed
except AnalysisException as e:
send_pagerduty_alert(f"Schema mismatch: {e}") # human wakes up at 3am
raise # pipeline halted until human intervenesThe traditional approach has two modes: success or human escalation. The agent-based approach has a spectrum: auto-resolve high-confidence changes, quarantine uncertain ones, escalate truly ambiguous cases. Most schema changes — the additive ones, the straightforward renames — never need a human at all.
The Confidence Boundary Pattern
The confidence threshold in the example above deserves its own framework, because it’s the most important design decision in any agent-based pipeline.
I call this the Confidence Boundary: the threshold below which an agent stops acting autonomously and escalates to either a more specialized agent or a human. Getting this wrong in either direction is costly:
- Boundary too high (e.g., 0.99): the agent escalates everything, and you’ve built an expensive alerting system disguised as an agent.
- Boundary too low (e.g., 0.50): the agent auto-applies bad fixes, and you’ve built a corruption engine.
The right boundary depends on the blast radius of a wrong decision:
| Pipeline Stage | Blast Radius | Recommended Confidence Boundary |
|---|---|---|
| Schema evolution (additive) | Low — worst case adds unused columns | 0.70 |
| Schema evolution (breaking) | High — can corrupt downstream models | 0.90 |
| Data quality (distribution drift) | Medium — may indicate real shift or bug | 0.80 |
| Data quality (null spike) | High — usually indicates upstream failure | 0.85 |
| Partition repair | Medium — can cause duplicate processing | 0.80 |
The principle: confidence boundaries should be inversely proportional to blast radius. Low-risk changes get auto-resolved aggressively. High-risk changes require near-certainty or human review.
In practice, I recommend starting with all boundaries at 0.90 and tuning down as you build confidence in each agent’s decision quality. Track the false positive rate (agent escalated unnecessarily) and false negative rate (agent auto-applied a bad fix) separately. You want the false negative rate near zero, even at the cost of a higher false positive rate.
The Voice AI Case: Real-Time Pressure Testing
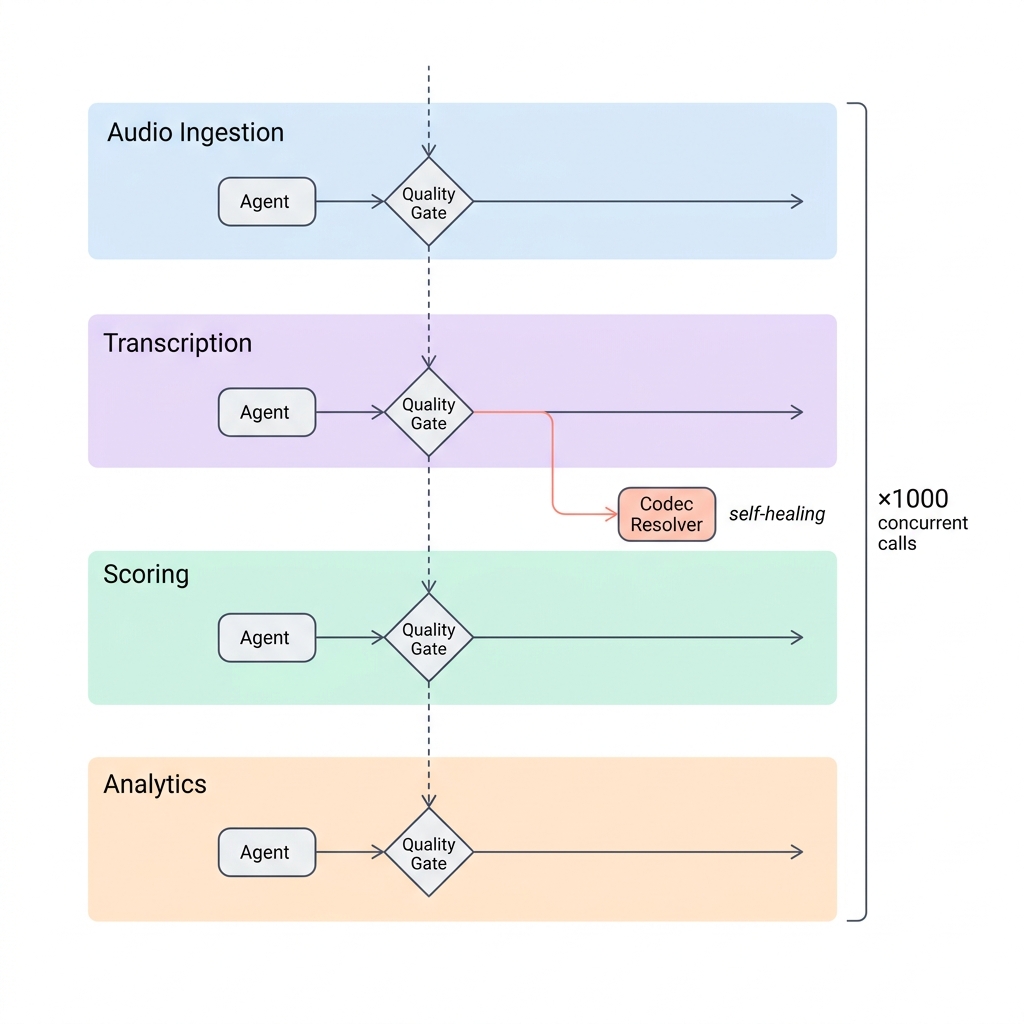
These patterns become essential when latency constraints tighten. At autoscreen.ai, we process real-time voice AI event streams where pipeline failures can’t wait for human intervention — calls are in flight, and degraded data means degraded user experience within seconds.
Each call produces four concurrent pipeline stages:
- Audio chunks streamed to a transcription service
- Transcription events fed to a scoring model
- Scoring results written to an analytics database
- Session metadata aggregated into dashboards
This is four pipeline stages running concurrently per call, multiplied by thousands of simultaneous calls. Traditional ETL falls apart here. You can’t batch-process audio in hourly Airflow runs. You can’t wait for a human to resolve a schema mismatch when 500 calls are in flight.
The agent-orchestrated approach:
┌─────────────┐ ┌──────────────┐ ┌───────────────┐ ┌──────────────┐
│ Ingestion │────▶│ Transcription │────▶│ Scoring │────▶│ Analytics │
│ Agent │ │ Agent │ │ Agent │ │ Agent │
└──────┬───────┘ └──────┬────────┘ └───────┬────────┘ └──────┬───────┘
│ │ │ │
▼ ▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐
│ Quality │ │ Quality │ │ Quality │ │ Quality │
│ Guard │ │ Guard │ │ Guard │ │ Guard │
└────┬─────┘ └────┬─────┘ └────┬─────┘ └────┬─────┘
│ │ │ │
└───────────────────┴──────────┬───────────┴─────────────────────┘
▼
┌──────────────┐
│ Escalation │
│ Agent │
│ (human-in- │
│ the-loop) │
└──────────────┘Each stage has its own quality guardrail tuned to its domain. The ingestion agent validates audio format and session metadata. The transcription agent checks for hallucination patterns — a real problem with streaming ASR where models occasionally confabulate words during silence or crosstalk. The scoring agent validates that output distributions haven’t drifted. The analytics agent ensures aggregations are consistent.
When the transcription agent detects a new audio codec it hasn’t seen before, it doesn’t crash — it hands off to a codec resolution agent, logs the decision, and continues processing other calls while the issue is resolved.
This is what “self-healing” actually means in production. Not magic. Not AGI. Just agents with clear responsibilities, calibrated confidence boundaries, and the ability to escalate.
Where This Breaks
Every architecture post should include a section on when the approach fails. Agent-based pipelines are no exception.
LLM latency in the hot path. An LLM call adds 200-2000ms of latency per decision. For batch pipelines processing hourly, this is negligible. For real-time streams requiring sub-100ms latency, it’s a dealbreaker. The mitigation: use LLM agents for policy decisions (schema evolution, anomaly classification) and deterministic code for per-record validation (null checks, type coercion). Don’t put an LLM call in a tight loop processing millions of records.
Hallucination in remediation. When a schema agent generates transformation SQL, it can hallucinate column names or invent joins that don’t exist. Recent research on agent hallucination shows that hallucinations in agent systems manifest not just as linguistic errors but as fabricated behaviors at every pipeline stage. The mitigation: always validate generated SQL against the actual schema before execution, run remediation on a sample batch first, and enforce the confidence boundary pattern described above.
Cost at scale. Each agent decision involves an LLM API call. At 67 incidents per month (Monte Carlo’s average), this is cheap. At 67 incidents per hour in a high-volume pipeline, costs compound quickly. The mitigation: cache agent decisions for recurring patterns. If the agent has seen the same schema drift three times, apply the cached remediation without an LLM call.
Complexity ceiling. A network of six agents with handoffs between them is understandable. A network of sixty is not. Agent systems can become as opaque as the pipelines they’re meant to improve. The mitigation: keep agent networks flat and shallow. A triage agent plus 3-5 specialist agents per pipeline boundary is the sweet spot. If you need more, you probably need to decompose the pipeline itself.
The accountability gap. When an agent auto-remediates a schema change and that remediation introduces a subtle data quality issue three stages downstream, who’s responsible? The agent’s tracing log shows what happened, but organizational accountability is still a human problem. Every auto-remediation should be logged, reviewable, and reversible.
Lessons From Both Ends of the Scale
I’ve built data pipelines at both extremes: Meta-scale batch processing (10TB+/day, Spark, Airflow) and real-time voice AI event streams (sub-500ms latency, LiveKit, streaming transcription). A few hard-won lessons:
Start with the contracts, not the agents. Define what “good data” looks like at each pipeline boundary before you make anything agentic. The agent layer is useless without clear success criteria. Data contracts — explicit schemas, SLOs on freshness and completeness, documented ownership — are the foundation. Research on schema evolution in data meshes shows that automated schema evolution reduces deployment time by 73% and error rates by 89%, but only when contracts are well-defined first.
Guardrails beat intelligence. A simple statistical check that catches distribution drift will save you more pain than a sophisticated LLM-powered anomaly detector. Use agents for the decisions (what to do when something breaks), not for the detection (noticing that something broke). Detection should be fast, deterministic, and cheap. Decision-making is where LLM reasoning adds genuine value.
Tracing is non-negotiable. In a multi-agent pipeline, you need to know exactly which agent made which decision and why. OpenAI’s SDK has this built in. If you’re building your own agent layer, invest in tracing before you invest in features. Meta’s recent work on AI-assisted pipeline knowledge mapping used 50+ specialized agents with multi-round critic passes — that system would be completely undebuggable without comprehensive tracing.
The handoff pattern is the whole game. The difference between a brittle pipeline and a resilient one is what happens when something unexpected occurs. Static DAGs crash. Agent networks route around the problem. But handoffs must be bounded — an agent should never hand off to more than 2-3 specialists, and handoff chains should never exceed 3 hops. Unbounded handoffs create circular delegation where agents pass problems to each other indefinitely.
Measure the gap, not the uptime. Pipeline uptime is a vanity metric. What matters is the Detection-Resolution Gap — the time between data going bad and data being fixed. Track this per pipeline stage. Organizations implementing automated recovery see a 76% reduction in MTTR and a 94% reduction in manual intervention. That’s the metric that tells you whether your agents are actually working.
What’s Next
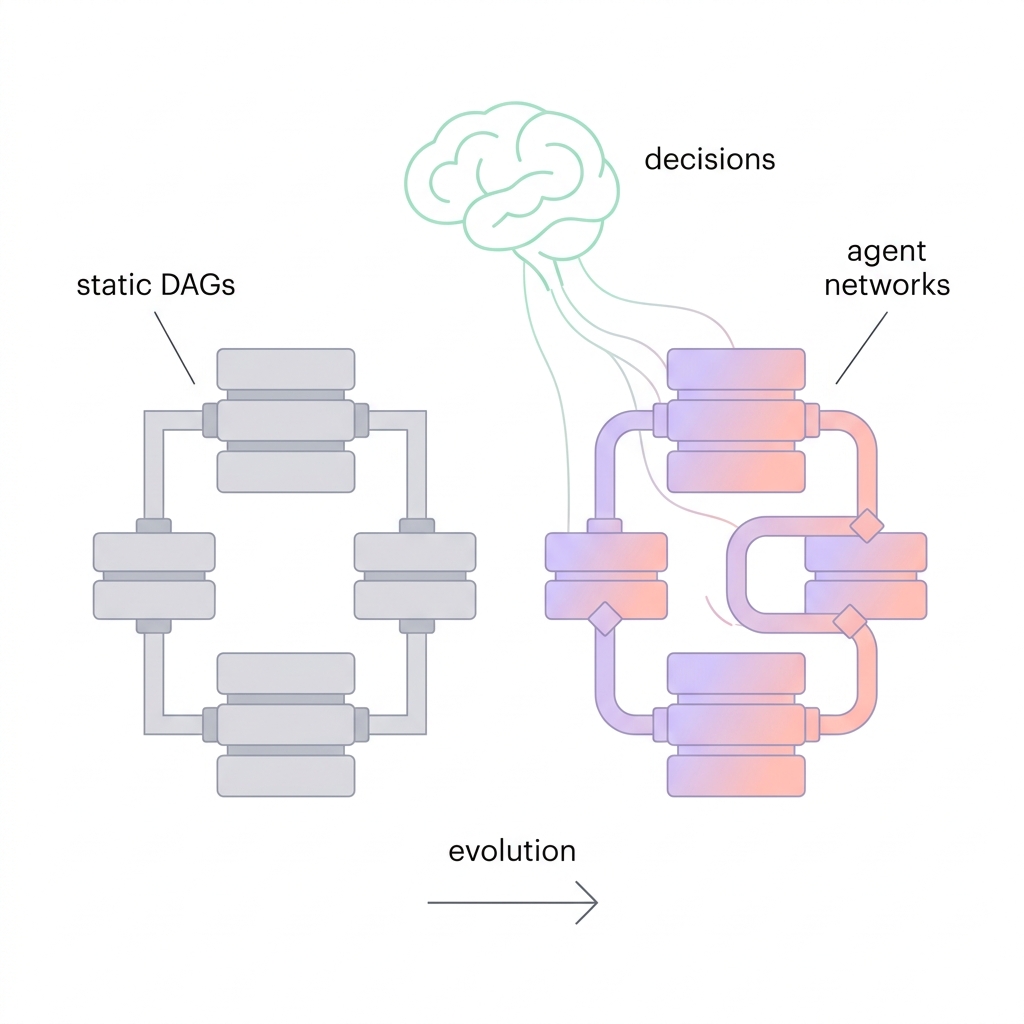
The trajectory is clear: data infrastructure is getting a decision layer. Not because LLMs are good at processing data — they’re not; Spark is still better at 10TB joins, and will be for the foreseeable future — but because LLMs are good at deciding what to do when the data is unexpected.
The next generation of data platforms won’t just execute pipelines. They’ll maintain contracts, detect violations, and take calibrated corrective action — all while maintaining the throughput and reliability that production systems demand. The tools are maturing: OpenAI’s Agents SDK and AgentKit provide the orchestration primitives; frameworks like Anthropic’s agent patterns, LangGraph, and CrewAI offer alternative approaches; and the data engineering ecosystem is converging on data contracts as the foundational abstraction.
The convergence I’m watching: data contracts + agent intelligence + confidence boundaries. When your pipeline stages declare typed contracts, agents can verify compliance at runtime and auto-remediate violations within calibrated confidence bounds. The contract tells the agent what “correct” looks like. The confidence boundary tells it when to act versus when to ask.
We’re not replacing data engineers. We’re closing the Detection-Resolution Gap — and finally giving data infrastructure the judgment layer it has always needed.
Sharad Jain is a data engineer and AI systems builder based in Bengaluru. He previously built data pipelines at Meta (10TB+/day) and founded autoscreen.ai, a production voice AI platform. He writes about the intersection of agentic AI and data infrastructure at sharadja.in.