My local QMD index currently spans five collections and 6,751 markdown documents. On the same machine, the runtime still warns that 2,105 of them need embeddings. That is the most honest possible opening for a post about building a second brain: the problem is not whether I have data. The problem is whether the retrieval system over that data is fast, sharp, and trustworthy enough to use every day.
Here is the live shape of the system right now:
| Layer | Live state |
|---|---|
| collections | 5 |
| indexed docs | 6,751 |
| docs still needing embeddings | 2,105 |
default brain ask path | BM25 fast path |
| measured fast-path latency target | ~340ms p95 |
| health model | telemetry + hourly doctor + tests |
Most “second brain” systems fail at the same layer: they treat memory as a note-taking problem.
That sounds reasonable until you have to actually use one under load. The real input stream is not curated notes. It is messy operational exhaust: Claude Code sessions, Chrome history, transcripts, raw docs, distilled summaries, wiki pages, shell commands, decisions, rejected approaches, and the half-finished reasoning that never makes it into a notebook.
The hard problem is not storage. The hard problem is turning that exhaust into a retrieval substrate that stays fast, legible, and useful when an agent or a tired human asks a question like:
- What did I decide about this auth flow three weeks ago?
- Where did I debug this exact failure?
- What was I reading when this idea showed up?
- Did I already reject this approach, and why?
A useful second brain is not a chatbot on top of notes. It is a pipeline. The pipeline ingests artifacts, normalizes them into stable documents, indexes them, embeds them, retrieves them with multiple search modes, exposes them through a narrow runtime surface, and then measures whether the whole thing is still working.
This is how mine is built today: QMD as the retrieval substrate, MCP as the protocol surface, brain.py as the thin runtime harness, and task surfaces that can serve both Claude Code and OpenClaw. The entire system is local-first, markdown-native, and instrumented enough to tell me when it is drifting.
If you want the shortest possible description, it is this:
messy artifacts
-> markdown normalization
-> partitioned corpus
-> qmd update (lexical index)
-> qmd embed (vector index)
-> lex / vec / hyde retrieval
-> brain CLI / MCP / skills
-> telemetry / doctor / acceptance gatesI call this pattern retrieval-first memory: memory that is optimized around recall quality, boundary clarity, and operational discipline, not around the fantasy that capture alone creates intelligence.
The post hangs on four reusable ideas:
| Concept | Definition |
|---|---|
| Retrieval-First Memory | optimize the system around recall quality and latency, not around capture volume |
| IR for Memory | normalize raw artifacts into markdown as an intermediate representation before retrieval |
| The Narrowest-Useful Query Rule | answer with the cheapest retrieval path that preserves enough precision |
| Anti-Rot Architecture | make the system continuously prove that its docs, telemetry, and runtime still match reality |
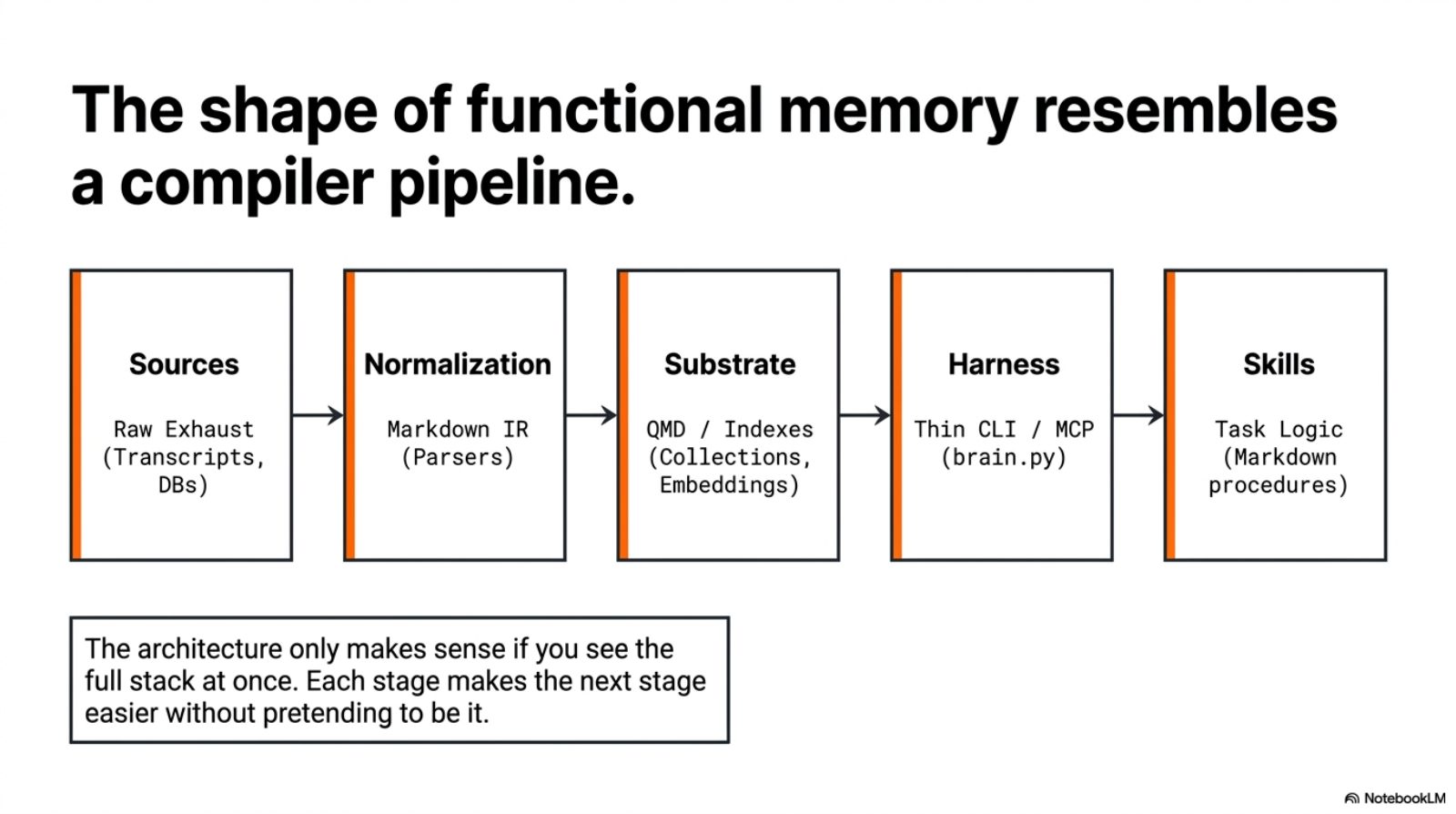
1. The System Shape
The architecture only makes sense if you see the full stack at once.
Sources
Claude Code JSONL sessions
Chrome History SQLite
raw docs / transcripts / imported research
distilled artifacts / wiki pages
|
v
Normalization
parsers -> markdown documents with frontmatter
|
v
Collections
brain
distilled
kb-wiki
kb-raw
chrome-history
|
v
QMD
qmd update -> BM25 / lexical index
qmd embed -> vector embeddings
qmd query -> hybrid retrieval + rerank
qmd search -> fast lexical path
|
v
Surfaces
MCP server surface
brain ask / recent / inbox / explain
Claude Code skills
|
v
Operations
usage.jsonl
doctor.sh
launchd jobs
acceptance checks
eval harnessThere are two clocks running through this system, and if you do not separate them, the whole thing becomes annoying fast.
| Clock | Latency budget | What runs on it | Why it exists |
|---|---|---|---|
| interactive clock | sub-second to a few seconds | brain ask, brain recent, brain explain, Stop-hook indexing, lexical retrieval | this is the path I have to trust while I am actively working |
| background clock | minutes to hours | distillation, Chrome history ingest, embedding refresh, doctor checks, acceptance reporting | this is the path that improves the corpus without blocking the work |
The split is deliberate. The Stop hook only does the cheap path: brain index --new --queue followed by qmd update. The heavy path lives in the cron/daemon layer: distill pending sessions, refresh browser history, then run qmd embed. That means the corpus becomes lexically searchable almost immediately, while the semantic layer catches up on the background clock.
This is the first non-obvious lesson in building a second brain: freshness and richness should not share the same latency budget.
The stack also has a clean ownership boundary at each layer:
| Layer | Owns | Explicitly does not own |
|---|---|---|
| sources | raw facts of what happened | any opinion about what matters |
| normalization | stable document shape, frontmatter, naming, file boundaries | ranking, retrieval policy, user-facing judgment |
| collections | corpus partitioning by information type | search logic |
| QMD | indexing, embeddings, retrieval modes, MCP serving | application workflow and product policy |
| brain runtime | validation, formatting, safety rails, telemetry, capture semantics | core retrieval engine behavior |
| skills | when to recall, when to capture, how to compose memory into larger tasks | deterministic I/O plumbing |
| operations | system health, regressions, drift detection | interactive answer quality directly |
That ownership table is more important than it looks. Most memory systems get mushy because every layer starts leaking into every other one:
- the ingestion layer starts doing premature summarization
- the retrieval layer starts making product decisions
- the app layer starts hiding corpus problems behind chat polish
- the operations layer is missing, so drift goes undetected
I am explicitly trying to avoid that. The shape I want is closer to a compiler pipeline than a note-taking app:
raw events
-> normalized documents
-> partitioned corpus
-> indexed substrate
-> surface-specific recallEach stage should make the next stage easier without pretending to be it.
There is another way to see the same architecture: as a sequence of lossy and lossless transformations.
| Stage | Lossless or lossy | Why it matters |
|---|---|---|
| JSONL session -> markdown session | mostly lossless | preserves turns, tool traces, project metadata |
| browser history DB -> daily markdown | selectively lossy | preserves what is useful for recall, drops browser-internal noise |
| session markdown -> distilled artifact | intentionally lossy | compresses toward goals, decisions, rejected approaches |
| corpus -> BM25 index | lossless with respect to text recall | ideal for exact-match questions |
| corpus -> vector embeddings | lossy semantic projection | useful for paraphrase, but never authoritative on its own |
That table explains why I keep both raw and distilled layers. Distillation is not a replacement for transcripts. It is a second representation optimized for a different retrieval problem.
There are four design choices carrying most of the weight here:
| Choice | Why it matters |
|---|---|
| Markdown as the canonical medium | It keeps the corpus inspectable, grep-able, and portable. The brain is not trapped in an opaque app database. |
| QMD as a shared retrieval substrate | One engine owns indexing, search modes, and MCP exposure rather than every surface reimplementing retrieval badly. |
| Thin harness, fat skills | The runtime stays deterministic and small. Task intelligence lives in markdown skill files and prompts. |
| Operational anti-rot | Telemetry, health checks, and acceptance gates prevent “it worked once” from being mistaken for “it is a system.” |
This last point matters more than people admit. A personal memory system does not die because indexing is impossible. It dies because the retrieval loop gets fuzzy, slow, stale, or annoying, and then you stop trusting it.
That leads to the first law:
the corpus precedes the interface.
If the underlying documents are noisy, unstable, or poorly partitioned, no chat UI will rescue the system.
2. Ingestion Is Not Capture
The input layer is heterogeneous by default. That is not a nuisance. It is the reality the architecture has to respect.
In my current system, the important source classes are:
| Source | Native format | What it contributes |
|---|---|---|
| Claude Code sessions | JSONL | decisions, code discussions, tool traces, debugging history, reasoning context |
| Chrome history | SQLite -> daily markdown | activity context, reading trails, visited URLs, search trails |
| raw knowledge artifacts | markdown files | imported papers, transcripts, research notes, external source material |
| distilled artifacts | markdown files | higher-signal abstractions: goals, decisions, rejected approaches, concepts, tags |
| wiki / synthesized pages | markdown files | stable concept pages and cross-document summaries |
The mistake most personal-memory systems make is to call “capture” the same thing as “ingestion.” It is not.
Capture is just getting bytes onto disk. Ingestion is turning those bytes into retrievable documents with stable shape.
That distinction is sharp enough to formalize:
| Stage | Question it answers | Typical failure if you stop there |
|---|---|---|
| capture | did the raw event land anywhere? | yes, but it is trapped in an app database, JSONL transcript, or browser internals |
| ingestion | can I deterministically parse it again later? | yes, but the output is still inconsistent and awkward to query |
| normalization | does it now have a stable schema, path, and document boundary? | yes, but it may still be too noisy |
| distillation | what should survive as compressed knowledge? | useful, but lossy and not authoritative on its own |
If you collapse those stages together, you lose the ability to reason about quality. You cannot tell whether a retrieval miss came from missing capture, broken parsing, bad document design, or an overly aggressive summary layer.
That is why the normalization layer matters so much. My session indexer in brain.py parses raw JSONL transcripts and emits markdown documents with:
- frontmatter:
session_id, date, project path, git branch, slug - user and assistant turns
- tool summaries
- extracted reasoning traces
- stable filenames and paths
That list sounds simple until you look at what the parser is actually doing.
For Claude Code sessions, the raw input is not a clean conversation transcript. It is a JSONL event stream with multiple record types and nested content blocks. The parser has to:
- scan every line defensively because malformed JSON lines can exist
- track metadata separately from content:
sessionIdcwdgitBranch- timestamps
- session slug from
systemrecords
- preserve user and assistant turns
- skip low-signal or non-text blocks like tool results and images
- extract only the tool inputs that matter for later recall
- preserve reasoning traces separately from final answers
The code is opinionated about what gets surfaced. Tool inputs worth keeping are things like:
ReadEditWriteGlobGrepBashWebSearchWebFetch
That is not an arbitrary list. It is a retrieval decision made at ingestion time. A future query like “what exact command did I run?” or “where did I grep for this symbol?” depends on those tool summaries existing as text in the normalized document.
The filename layer matters too. The session indexer uses per-agent prefixes so different sources can coexist in one corpus without stomping each other:
| Agent source | Output naming strategy |
|---|---|
| Claude | bare stem for back-compat |
| Codex | codex__... prefix |
| Gemini | gemini__... prefix |
| Cursor | cursor__... prefix |
That is a small detail, but it is the kind of small detail that prevents a corpus from rotting as new sources are added.
Chrome history gets transformed into one markdown file per day, with timestamps, domains, page titles, and search traces. Distillation produces another layer of markdown artifacts that compress a session into what actually matters later: goals, decisions, rejections, files touched, technologies, and concepts.
Chrome ingestion is a different normalization problem entirely. The raw source is a local SQLite database, not a transcript. The ingest script first copies the browser database to a temp path so Chrome’s file lock does not block reads. Then it joins together multiple tables:
- visits
- URLs
- context annotations
- content annotations
- keyword search terms
- cluster labels
That joined view is then grouped into one markdown file per day.
That “one file per day” choice is not just aesthetic. It is the document-boundary answer for browser memory. Sessions want one file per session. Browsing history wants one file per day. Those are different units of recall.
The Chrome pipeline is also aggressively selective. It applies:
- allowlists for productive domains
- suffix-based domain matching for subdomains
- NSFW filtering on URLs, titles, and searches
- de-noising for spammy or injected search terms
- omission of Chrome-internal URLs and local file URLs
That is normalization as policy. If you do not make those cuts early, your corpus inherits the browser’s worst qualities: ad noise, accidental clicks, internal URLs, and junk search fragments.
This is why I think of normalization as a schema design problem, not a file conversion problem.
You are deciding, for each source:
| Decision | Example in this system |
|---|---|
| document boundary | one session per file, one browser day per file |
| stable identity | session stem, agent prefix, date path |
| metadata contract | frontmatter fields that will exist everywhere for that source |
| signal filter | which tool calls, URLs, titles, searches, and blocks are worth preserving |
| path semantics | where in the corpus this source will live so later retrieval can reason about it |
Once you see ingestion that way, a lot of second-brain systems start looking suspiciously under-specified. They say “we ingest everything,” but they do not define:
- what a document is
- what the stable key is
- what gets dropped
- what fields are guaranteed
- how two source types differ structurally
Without that, retrieval quality becomes accidental.
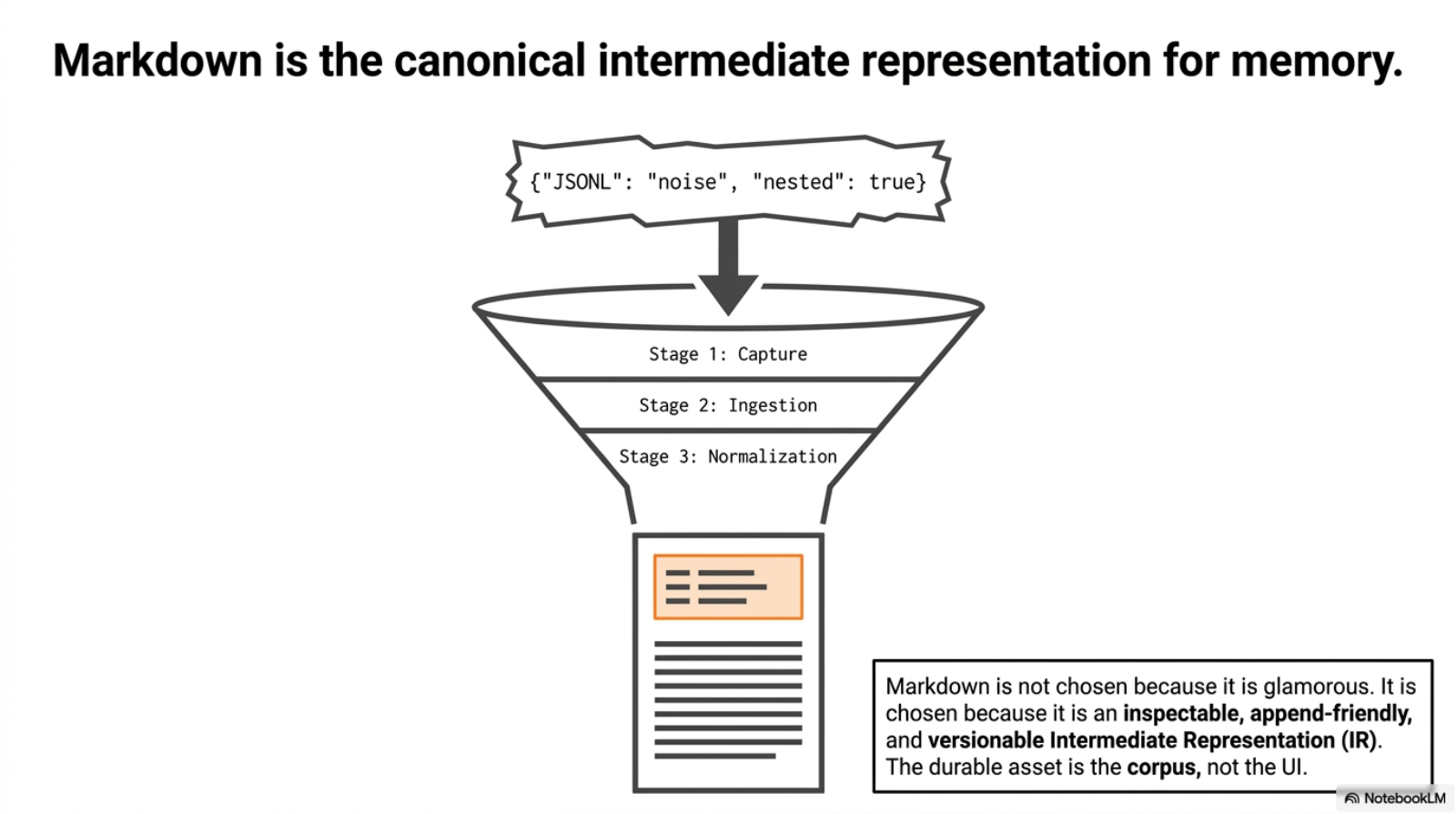
I think of markdown here as IR for memory: an intermediate representation between raw event logs and retrieval. Not because markdown is glamorous. Because it is inspectable, versionable, and composable.
And like any good IR, it should satisfy a few properties:
| Property | Why it matters |
|---|---|
| human-readable | I can inspect bad outputs directly |
| append-friendly | new artifacts can land without schema migrations |
| stable enough for indexing | BM25 and embedding layers need predictable text structure |
| rich enough for provenance | source, date, project, and session identity must survive |
| cheap to diff | regressions in parsers or distillers need to be visible in git or plain text |
That one design choice buys a lot:
- QMD indexes it natively.
- agents can quote or retrieve from it directly.
- I can grep it when retrieval fails.
- I can diff it when distillation goes bad.
- I can move collections around without migrating a proprietary store.
There is also a deeper benefit: markdown keeps the memory substrate debuggable by the same tools I already trust for code. rg, sed, awk, git diff, filesystem walks, and plain editors all still work. That sounds almost trivial until you compare it to agent-memory systems that immediately disappear behind a vector DB, a hosted API, or an opaque “memory sync” abstraction.
This is also why I do not treat the second brain as “an app.” The durable asset is the corpus, not the UI.
3. Collections, Indexing, and Embeddings
Once the corpus is normalized, the next question is how to split it so retrieval does not collapse into an undifferentiated soup.

My live QMD config currently registers five collections:
| Collection | Path role | Retrieval role |
|---|---|---|
brain | raw indexed sessions | high-recall verbatim memory |
distilled | dense LLM-generated artifacts | semantic compression of prior work |
kb-wiki | synthesized wiki pages | stable high-level concepts |
kb-raw | raw articles and transcripts | source-level grounding |
chrome-history | browsing logs | behavioral and temporal context |
At the moment of writing, the live file counts look like this:
| Collection | Live file count | What that count implies |
|---|---|---|
brain | 4,470 | the largest, noisiest, and most lossless layer dominates raw recall |
distilled | 778 | much smaller, denser, and more semantic |
kb-wiki | 216 | slow-moving synthesized knowledge |
kb-raw | 1,846 | long-tail source grounding |
chrome-history | 86 | low-count but high-temporal-value context |
Those counts are not just scale metrics. They are retrieval-shape metrics. A corpus dominated by raw transcripts behaves differently from one dominated by polished notes, even if both use the same engine.
That split is not cosmetic. It is what allows retrieval to preserve the difference between:
- exact prior transcript recall
- compressed lessons
- source documents
- browsing exhaust
- stable knowledge pages
Collection boundaries answer three questions at once:
| Question | Why it matters |
|---|---|
| what kind of artifact is this? | transcript, distillation, wiki page, source text, or behavioral exhaust |
| how should this artifact compete? | a raw session should not rank the same way as a distilled decision memo |
| what kind of recall is this layer good at? | exact-match, semantic, provenance-heavy, or recency-oriented |
Without that partitioning, retrieval becomes a false democracy where every file fights in the same pool even though the documents were created for different jobs.
QMD is the retrieval substrate sitting under all of this. The repo describes it as an on-device search engine for markdown knowledge bases that combines BM25 full-text search, vector semantic search, and local reranking QMD. In practice, my pipeline uses it in two phases:
1. qmd update
-> refreshes the lexical / BM25 index
2. qmd embed
-> refreshes vector embeddingsThose two commands are easy to say and easy to blur, but they are not the same freshness guarantee.
| Command | What it refreshes | Operational meaning |
|---|---|---|
qmd update | lexical / BM25 visibility of changed files | the corpus is text-searchable again |
qmd embed | semantic vector representation | embedding-based retrieval can now see the new or changed material |
That means “the index is fresh” is actually two claims:
- lexical freshness: newly normalized text can be retrieved at all
- semantic freshness: embedding-based retrieval paths know about that text too
In my stack, lexical freshness has the stricter SLO. That is why the cheap path runs in the Stop hook and the richer path runs on the background clock.
The automation loop reflects that split directly:
brain index --new --queue
brain distill --from-pending
chrome_history_ingest.py
qmd update
qmd embedThe timings in the surrounding scripts and docs make the separation concrete:
| Step | Budget class in this system |
|---|---|
Stop-hook index --new --queue + qmd update | < 2s target so it stays invisible in active work |
async qmd update | around ~5s |
async qmd embed | around ~17s per batch and model-dependent |
This is why I keep insisting the second brain is a pipeline. Pipelines have critical paths. Some stages can lag; some cannot.
That sequencing matters. You do not embed raw chaos directly. You first normalize and organize the corpus, then reindex, then refresh embeddings.
It is also worth stating the less fashionable truth: embeddings are not the system. They are one retrieval mode inside the system.
| Layer | What it does | Why it exists |
|---|---|---|
| lexical index | exact term / path / command recall | unbeatable for commands, filenames, literal phrases |
| vector index | semantic proximity | useful for paraphrase and conceptual search |
| rerank stage | candidate ordering | helps separate “technically related” from “actually relevant” |
Those layers fail differently, which is exactly why I do not want to collapse them into one magical “search” box.
| Failure shape | Typical cause | Better fix |
|---|---|---|
| exact phrase exists but is not surfaced | lexical ranking or collection scope is weak | BM25 tuning or narrower corpus partition |
| conceptually related but wrong answer ranks high | semantic neighborhood is too broad | reranking or a more constrained query path |
| semantically useful hit is missing | embeddings are stale or the semantic layer is too thin | qmd embed, HyDE, or stronger distillation |
| answer exists but is buried in huge transcripts | raw layer is too lossless for the query | lean on distilled artifacts |
There is a reason the runtime still defaults brain ask to the BM25 fast path rather than always using a hybrid query. In the live implementation, the lexical path is dramatically cheaper and faster. The code explicitly describes the wedge as a BM25-first path with p95 around ~340ms, while the fuller hybrid query and rerank path is slower and reserved for later selection logic.
That is not a compromise. It is a design judgment that also lines up with Anthropic’s public guidance on agents: prefer simple, composable patterns first, and only add complexity when measurement says the simple path is insufficient Anthropic.
The important nuance is this: the default is not “BM25 because vectors are bad.” The default is “BM25 because defaults are about reliability under real latency budgets.”
There is also a corpus-design reason the lexical path works better here than people might expect. The normalized documents are already shaped around:
- sessions
- decisions
- tool traces
- dates
- projects
- concepts
BM25 is not operating over random sludge. It is operating over documents deliberately engineered to make lexical recall useful.
That becomes the second law:
retrieval quality is constrained by latency budgets as much as by embeddings.
If a memory system is semantically elegant but too slow for habitual use, it has failed.
4. Retrieval, Search, and Reranking
This is the layer people hand-wave most often. “We use hybrid search” is not an architecture. It is a slogan.
The retrieval stack here is more usefully understood as a ladder:
| Mode | Best query shape | Failure mode |
|---|---|---|
lex | exact terms, commands, file paths, literal errors | misses conceptual paraphrases |
vec | semantic recall, paraphrases, concept-level search | may retrieve vaguely related but wrong material |
hyde | ”a session where we…” style memory prompts | can be powerful, but easier to overfire or drift |
| rerank | sort promising candidates | helps precision, but costs latency |
What matters in practice is not just which modes exist. It is how the runtime chooses among them, constrains them, and recovers when they fail.
QMD exposes all three retrieval modes, and the official docs position MCP as the standard way for AI applications to connect to external systems like files, tools, and workflows MCP. The practical consequence is that the same markdown corpus can be queried either:
- locally via
qmdcommands - through the MCP server surface
- or via a thin runtime wrapper like
brain ask
That layering is the whole point.
The fastest path in my stack today is not “semantic everything.” It is:
query
-> validate and sanitize
-> qmd search --json
-> take top lexical candidates
-> attach freshness metadata
-> format for terminal or agent surfaceThat simplified path hides a real sequence of policy decisions in the runtime:
| Step | What the runtime is actually doing |
|---|---|
| query intake | join free-text args into one query string |
| validation | reject dangerous shell-shaped input like raw ;, backticks, or $( |
| bounded search | call qmd search --json with a candidate limit larger than final top-k |
| candidate shaping | parse JSON hits, resolve paths, attach age/freshness metadata |
| filtering | optionally cut by age via --since-days |
| surface formatting | terminal-friendly prose or machine-readable JSON envelope |
| telemetry | log query length, latency, surfaced paths, hit count, and surface |
That is why I treat retrieval policy as a first-class surface. The engine may know how to search, but the runtime decides what “a safe, useful answer” looks like.
That is enough to answer a surprising fraction of memory questions, especially when the corpus is already structured around sessions, decisions, and tool traces.
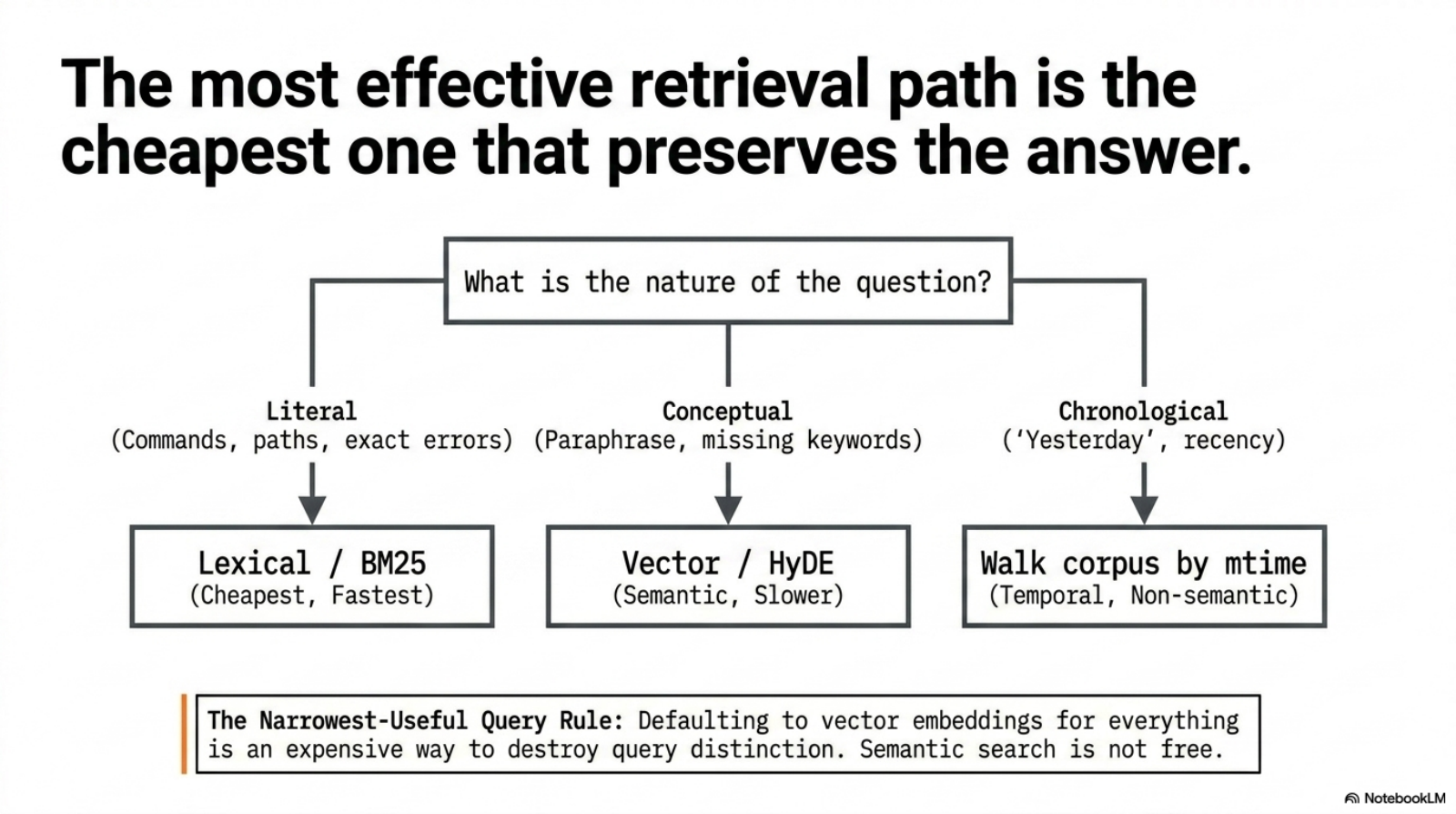
Why not just use semantic search for everything?
Because semantic search is not free and not always the right primitive.
| Question | Best retrieval mode | Why |
|---|---|---|
”where did I run qmd embed -f?“ | lexical | exact command recall |
| ”what was the session where I chose the CLI wedge?“ | lexical + distilled | decision phrases are often explicit |
| ”find the session where I was debugging the memory system but did not use the phrase memory system” | vector or HyDE | conceptual query, paraphrase-heavy |
| ”what was I doing yesterday?“ | recency walk over collections | a chronological query, not a semantic one |
That last row matters. Not every memory query is “search” in the same sense. Some are temporal, some are behavioral, some are provenance checks.
This is why I think of the query layer as a routing problem before it becomes a ranking problem.
If the question is:
- literal -> prefer lexical
- conceptual -> consider semantic / HyDE
- chronological -> walk the corpus by mtime and collection
- provenance-heavy -> preserve path, source, and freshness above fluency
Too many memory products skip that routing layer and jump straight to “semantic search everywhere.” That is usually just an expensive way to destroy the distinction between query types.
This is why I use the term retrieval discipline: choosing the narrowest search surface that answers the question without incurring unnecessary latency, token cost, or fuzziness.
Put differently: The Narrowest-Useful Query Rule says the best retrieval path is the cheapest one that still preserves the answer. grep beats embeddings when the question is literal. BM25 beats hybrid search when the corpus is already well-shaped and the query is explicit. A chronological walk beats both when the question is temporal.
The runtime also bakes in a provenance policy. brain ask does not just print a title and a snippet. It attaches:
- the
qmd://...path - score
- age label like
today,yesterday, orN days ago - a freshness warning when the memory is old enough to be risky
That is retrieval policy doing product work. A raw ranking score is not enough when the underlying artifact may describe code that has already changed.
There is a second layer of discipline here: error handling is part of retrieval quality, not a separate concern.
| Failure mode | Runtime behavior |
|---|---|
| bad query | reject with structured exit code and a repair hint |
qmd missing | explicit install / reindex recovery path |
| timeout | emit qmd_timeout, log telemetry, preserve the failure as data |
| invalid JSON from the engine | fail loudly instead of pretending results are empty |
| no results | return structured empty response rather than fabricating a summary |
That matters because a second brain can fail in ways that look deceptively intelligent. A silent timeout or malformed engine response is worse than a hard failure if the caller interprets the absence of evidence as “nothing exists.”
The benchmark harness around this system also reinforces the point that retrieval is not one monolithic number. Even the local evaluation setup distinguishes:
inproc-bm25qmd-lexqmd-hybrid
That is the right shape. If you cannot decompose retrieval into separate modes and measure them independently, you do not really know what your memory layer is good at.
In other words:
retrieval quality is the product of routing, ranking, provenance, and failure semantics together.
5. QMD vs Brain MCP vs Brain CLI
These names are easy to blur, so the boundary needs to be explicit.
| Layer | Responsibility | What it is not |
|---|---|---|
| QMD | indexing, search, collections, embeddings, hybrid retrieval, MCP serving | not my product logic |
| brain MCP | the memory corpus exposed through QMD’s MCP surface | not a separate magical reasoning engine |
brain.py / brain CLI | query shaping, safety rails, formatting, telemetry, health introspection, inbox capture | not the core search engine |
| skills | task-specific workflows and agent intent | not the deterministic runtime |
That table is the minimum version. The fuller version is about surface contracts.
| Surface | Input shape | Output shape | Primary consumer |
|---|---|---|---|
qmd search | plain query string | BM25 JSON or text hits | fast local runtime paths |
qmd query | expanded or structured lex/vec/hyde document | hybrid reranked results | richer retrieval workflows |
qmd mcp | MCP stdio protocol | tools/resources exposed to an MCP client | Claude Code or another MCP client |
brain ask | CLI args / env vars | terminal prose or structured JSON envelope | me, scripts, Claude Code skills |
brain explain | no query, just runtime invocation | live system state | debugging, drift detection, operator trust |
| skill invocation | natural-language task intent | delegated call into brain.py or QMD-backed behavior | agent workflow layer |
Once you look at the contracts, the confusion gets easier to resolve. QMD and brain.py are not competing interfaces. They are adjacent layers in the same stack.
The cleanest way to say it is:
QMD owns retrieval.
brain.py owns runtime behavior.
skills own task-level judgment.I would make the same distinction one level more concretely:
| If you need to… | The owning layer is… |
|---|---|
| add a new corpus folder | QMD config / collection layer |
| change how recall is formatted for a human or agent | brain.py |
| change when memory should be consulted inside a workflow | skill layer |
| change how embeddings or hybrid retrieval work | QMD, not the CLI wrapper |
| explain why the system is broken right now | brain explain and the ops layer |
This is also why “brain MCP server” is easy to misunderstand. In my actual local setup, the MCP surface is effectively QMD pointed at the brain-owned collections. The runtime layer around it is where I add:
- query validation
- output envelopes
- staleness warnings
- KAIROS-style inbox capture
- usage logging
- doctoring and explainability
The command line reflects that separation clearly. qmd itself exposes:
qmd searchqmd vsearchqmd queryqmd getqmd multi-getqmd mcp
That is the substrate surface.
brain.py then exposes a different shape entirely:
indexdistillqueueaskrecentinboxexplain
Those are not alternative spellings for the same thing. They are wrapper surfaces around different responsibilities:
brain.py command | Type of responsibility |
|---|---|
index, distill, queue | corpus production / maintenance |
ask, recent | retrieval access with runtime policy |
inbox | typed capture into a memory-friendly path scheme |
explain | self-description and operator diagnostics |
One concrete example: brain ask adds a memory-age label like today, yesterday, or N days ago, and only emits a freshness warning when a memory is older than a day. That is not indexing. It is runtime policy. It is the kind of detail a memory tool needs if it is going to be trusted by either a person or an agent.
Another: brain explain is not retrieval at all. It is the self-diagnosis surface. It reports live state: QMD presence, collection visibility, launchd job status, inbox state, installed skills, telemetry tail. That is how you stop docs from becoming lies.
That matters because a second brain has two very different kinds of truth:
| Truth type | Example |
|---|---|
| corpus truth | what documents exist and what they contain |
| runtime truth | what is currently installed, indexed, loaded, routed, healthy, and stale |
QMD mostly owns corpus truth. brain explain is there to expose runtime truth.
I think of this as surface separation:
- the substrate should search
- the harness should normalize runtime behavior
- the skill should decide when the memory surface is worth invoking
The last piece is the skill layer, because this is where many agent-memory systems become conceptually sloppy. A skill is not “more retrieval.” A skill is activation logic plus task framing.
In my current setup, the installed brain skills carry path-scoped activation rules like:
brain-askonly activates in~/Projects/**brain-recentonly activates in~/Projects/NOW/**brain-inboxis unconditional
That means the skill layer is doing something the search engine should never do: deciding when the memory surface belongs in the conversation at all.
So the boundary line I care about most in this section is:
QMD decides how to search. The runtime decides how to expose. The skill decides when to bother.
6. Thin Harness, Fat Skills
Garry Tan’s “thin harness, fat skills” idea lands because it matches what high-functioning agent systems actually need: a small deterministic runtime and a rich task layer expressed in the medium the model already reads well Garry Tan.

The most important sentence in that whole framing is not “skills are powerful.” It is the more uncomfortable one: the bottleneck is usually not model intelligence, it is schema understanding.
If the model cannot find the right context, load the right procedure, or distinguish deterministic work from judgment work, a bigger model mostly just fails more fluently.
The harness in my system stays deliberately narrow:
- parse arguments
- validate inputs
- shell out to QMD safely
- format results
- write telemetry
- expose debug state
The skills stay fat:
- when to invoke retrieval
- what retrieval mode is implied by user intent
- how to combine memory with a broader task
- what not to save
- how to route capture versus recall
That thin/fat distinction is easy to repeat and easy to misuse, so I try to define it operationally:
| Layer trait | ”Thin” means… | ”Fat” means… |
|---|---|---|
| logic density | small amount of deterministic branching | rich procedural and judgment-heavy instructions |
| change frequency | should change rarely and carefully | can evolve quickly with workflow learning |
| failure cost | failures are systemic and should be obvious | failures are task-local and easier to iterate on |
| best representation | code, exit codes, I/O contracts, file paths | markdown procedures, descriptions, heuristics, routing language |
| consumer | shell, scripts, launchd, other tools, agent wrappers | the language model itself |
That table is why markdown skills are not an afterthought here. They are the place where I want to put:
- process
- judgment
- activation hints
- scope
- exceptions
- task-specific language
And it is why I do not want to put those things into the harness unless I absolutely have to.
That split matters for at least three reasons.
| Reason | Thin harness benefit | Fat skill benefit |
|---|---|---|
| maintenance | less code drift in the runtime | workflow logic evolves without recompiling the system |
| agent ergonomics | predictable commands and exit codes | rich behavioral guidance close to the task |
| context hygiene | fewer abstractions in code | more judgment in markdown, where the model can actually use it |
There is also a fourth reason: debuggability asymmetry.
If a thin harness fails, I want it to fail in a way that looks like software:
- bad exit code
- timeout
- malformed JSON
- missing binary
- lock contention
If a fat skill fails, I want it to fail in a way that looks like judgment:
- wrong invocation timing
- over-retrieval
- under-retrieval
- bad decomposition of the task
- poor phrasing of what to capture or recall
Those two failure classes should not be mixed. If the harness is bloated with task judgment, then every product mistake starts masquerading as an infrastructure bug.
It also lets the system support multiple surfaces without forking the architecture. A terminal call, an MCP query, and a Claude Code skill can all hit the same retrieval substrate while preserving different surface behaviors.
In the live stack, you can see that separation directly:
| Installed skill | Scope rule | Why it belongs in the skill layer |
|---|---|---|
brain-ask | ~/Projects/** | project-scoped recall is an activation decision, not a search-engine concern |
brain-recent | ~/Projects/NOW/** | ”recent” is relevant when the project context itself is active |
brain-inbox | unconditional | capture should remain globally available |
Those path filters are exactly the sort of thing people are tempted to push downward into the runtime. I think that is a mistake. A path-scoped activation rule is not a retrieval primitive. It is workflow policy.
That is the key distinction between a usable agent memory system and a pile of plugins:
the harness should be boring; the skills should be opinionated.
I would rather add a new skill than add a new mini-platform inside the runtime. The moment the harness starts swallowing retrieval strategy, agent policy, user workflow logic, and product opinions, it becomes the wrong kind of thick.
There is a simple decision rule I use for where new behavior belongs:
| If the new behavior is mostly… | Put it in… |
|---|---|
| deterministic lookup, validation, or formatting | the harness |
| natural-language routing, judgment, or task decomposition | a skill |
| index structure, search mode, or retrieval mechanics | QMD / substrate layer |
Examples make this clearer:
| Behavior | Right layer | Why |
|---|---|---|
| reject a query containing shell-injection markers | harness | deterministic safety check |
| decide that “what was I doing today?” should invoke a recent-activity workflow | skill | intent routing |
add today / yesterday / N days ago freshness labels | harness | surface policy with deterministic rules |
| decide whether this note is worth saving or is just derivable noise | skill or capture-policy layer | judgment-heavy |
hybrid lex/vec/hyde retrieval behavior | QMD | engine capability |
This section also answers a more strategic question: why not just make the harness smarter and keep fewer skills?
Because thick harnesses age badly.
They accumulate:
- duplicated workflow logic
- hard-to-reason branching
- more hidden behavior per command
- more context assumptions inside code
- more places where agent and operator expectations diverge
Skills, by contrast, let the system expose its own procedure in the same medium the model reasons over. A good skill is part codebook, part resolver, part operating manual.
That is the doctrine in one line:
push intelligence up into skills, push execution down into deterministic tooling, and keep the harness narrow enough that you can still trust it.
7. Audit Your Own Stack
If you want to build this without copying my exact tooling, do not start by designing a beautiful assistant. Start by auditing the memory path you already have.
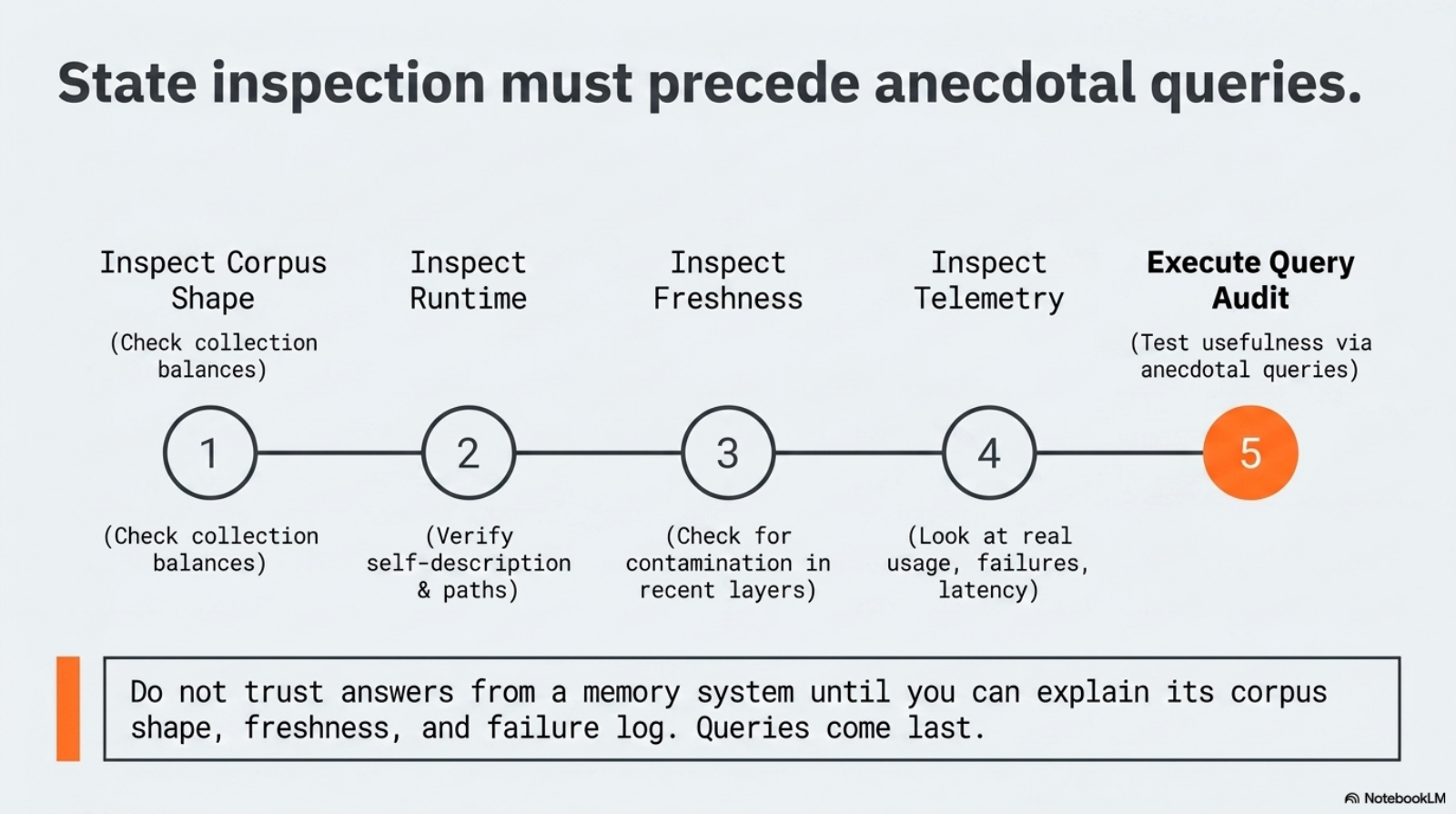
Run five checks, in this order:
| Check | What you are looking for | Failure meaning |
|---|---|---|
| artifact audit | what raw sources already exist: sessions, browser history, docs, transcripts, notes | you may not have a memory problem yet; you may have a capture problem |
| normalization audit | which of those sources already become stable text or markdown documents | your retrieval substrate does not exist as inspectable documents |
| freshness audit | how quickly changed artifacts become visible lexically and semantically | your corpus exists, but the runtime is reading a lagging copy of reality |
| retrieval audit | which questions require exact recall, semantic recall, recency, or provenance | you are overloading one retrieval mode to solve incompatible query classes |
| surface audit | what is the thinnest interface you will actually use every day | the system may be technically sound but behaviorally dead |
That sequence matters. If you start with the assistant layer, you hide failures from the layers below it. An LLM surface can make a broken substrate look functional for a surprisingly long time.
On my machine, the fastest useful audit looks like this:
qmd collection list
python3 ~/.brain/brain.py explain
python3 ~/.brain/brain.py recent --since=24h --json
tail -20 ~/.brain/logs/usage.jsonlI intentionally left brain ask out of that first pass here. An audit should start with state inspection, not with an anecdotal query. A single good query can hide a stale index, a polluted recency layer, or dead telemetry. State comes first. Queries come after.
7.1 Corpus Inventory
qmd collection list answers the first operator question: what corpus shape am I actually searching?
On my machine right now, it returns:
| Collection | Files | Updated | What I infer |
|---|---|---|---|
brain | 4,470 | 31m ago | the raw session layer dominates recall and noise budget |
distilled | 778 | 6d ago | semantic compression exists, but it is stale relative to the raw layer |
kb-wiki | 216 | 1d ago | stable concept pages are updating slowly, which is fine |
kb-raw | 1,846 | 6h ago | source-level grounding is alive and changing |
chrome-history | 86 | 6d ago | temporal browsing context is behind and should not be trusted as fresh |
That one command is already more diagnostic than many dashboards because it exposes three properties simultaneously:
- corpus balance: which layer dominates the candidate pool
- freshness skew: which layers are drifting behind others
- document-boundary sanity: whether collection counts move the way the source type should move
The red flags are specific:
- if
brainis exploding whiledistilledstays flat forever, the compression layer is not keeping up - if
chrome-historyhas not moved in days, any answer framed as “recently watched” or “recently searched” is suspect - if a supposedly stable layer swings wildly in count, document boundaries may be wrong
The point of the collection audit is not “wow, lots of files.” The point is to understand what kind of competition your retrieval engine is about to run.
7.2 Runtime Explainability
python3 ~/.brain/brain.py explain answers the second operator question: can the runtime explain its own installation state without me reading code?
The current output on my machine includes:
brain.pyversion0.1.0- Python path and version
BRAIN_HOME,BRAIN_INBOX_DIR, andBRAIN_SURFACE- QMD binary resolution
- registered collection names
- today’s inbox path
- telemetry path, mode, and recent events
- launchd job status
- installed Claude Code skills and their scope rules
- last doctor tail
That is not cosmetic introspection. It is a contract test for the runtime’s own assumptions.
I use explain to answer five concrete questions:
| Question | Example from the current output |
|---|---|
| am I running the right binary? | /Users/sharad/.brain/brain.py under Python 3.14.3 |
| am I pointing at the right home and inbox? | BRAIN_HOME=/Users/sharad/.brain, inbox under /Users/sharad/.brain/inbox/... |
| is QMD reachable from this environment? | /opt/homebrew/bin/qmd resolves |
| are the background jobs alive? | com.brain.doctor and com.brain.week1 are loaded with last_exit=0 |
| are the surfaces actually installed? | brain-ask, brain-recent, and brain-inbox show up with their scope rules |
The subtle but important part is skill scope. If brain-ask is only active under ~/Projects/** and brain-recent is only active under ~/Projects/NOW/**, then “the assistant did not use memory” might not be a retrieval failure at all. It might be a surface-activation failure.
This is why I treat explainability as a production feature. A system that cannot report its own environment, surfaces, and health boundaries forces every failure into source-code debugging.
7.3 Freshness and Shape Audit
python3 ~/.brain/brain.py recent --since=24h --json answers a harder question than “is the system alive?”:
What kinds of artifacts became visible recently, from which collections, and how contaminated is the recency surface?
The current output shows:
total: 22walk_ms: 54- heavy presence of
brainitems from benchmark and answer-eval sessions - recent
kb-rawadditions such as:claude-code-leak-deep-lifts-2026-04-28gbrain-evals-frameworks-2026-04-28
That is exactly why I prefer a JSON audit path here instead of a pretty human summary. I want to inspect recent shape, not just admire that something came back.
There are three things I look for in recent output:
| Signal | Healthy interpretation | Failure interpretation |
|---|---|---|
| walk time | low double-digit or low triple-digit milliseconds for a 24h scan | recency is too expensive to use interactively |
| collection mix | recent artifacts appear from the layers I expect to be moving | one ingestion path is dead or one layer is starving all others |
| artifact type quality | recent items look like meaningful sessions, docs, or notes | the surface is polluted by synthetic eval debris, spam, or malformed outputs |
This is where many memory systems quietly degrade. The recency surface becomes dominated by whatever pipeline writes the most files, not by what the operator most needs to see. In my case, benchmark-style synthetic sessions can easily crowd out higher-value human work if I do not watch the shape of the recent layer.
That is why recent is not just a convenience command. It is a surface-quality audit.
7.4 Telemetry Audit
tail -20 ~/.brain/logs/usage.jsonl answers the final operator question: what did the system actually do, and how did it fail under real use?
The recent telemetry on my machine shows:
- repeated
doctor_runevents - one
askwithquery_len: 35,latency_ms: 363,n_hits: 0 - one
recentrun withwalk_ms: 38,n_total: 24 - two
inbox_writeevents - one
doctor_runfailure withmap_drift - one
doctor_runfailure withunittest_failed
That small tail already tells me five useful things:
| Observation | What it means |
|---|---|
ask returned n_hits: 0 in 363ms | low latency alone does not prove useful recall |
recent completed quickly | the recency walk is currently interactive enough |
inbox_write events exist | the capture path is not dead |
map_drift occurred once | docs and code briefly disagreed and the doctor caught it |
unittest_failed occurred once | health checks can surface transient or flaky runtime issues before they become folklore |
Telemetry is where the difference between “it demos” and “it operates” becomes obvious. If your usage log only records success, it is not telemetry. It is vanity analytics. The minimum viable memory log should tell you:
- which surface was used
- which operation ran
- how long it took
- whether it returned anything
- whether health checks failed
- whether the system is being used at all
7.5 Query Audit Comes Last
Only after those four state checks do I run an actual retrieval query such as:
python3 ~/.brain/brain.py ask "qmd embed"Running a query too early confuses diagnosis. A good hit can coexist with:
- stale embeddings in another collection
- broken daily-log capture
- dead launchd jobs
- recent-surface pollution
- silent drift between docs and code
The query audit is where I test user-visible usefulness. It is not where I establish system health.
So the real audit order is:
- inspect corpus shape
- inspect runtime self-description
- inspect recent-layer freshness and contamination
- inspect telemetry and failures
- only then inspect query usefulness
That ordering sounds conservative because it is. Most second-brain projects fail by building the assistant before they have built the corpus.
If you are building from scratch, the safe order is:
- pick one raw source that already exists
- normalize it to markdown with stable frontmatter
- index it lexically first
- only then add embeddings
- only then add a CLI or agent surface
If I had to compress the audit logic into one rule, it would be:
do not trust answers from a memory system until you can explain its corpus shape, freshness, recent surface, and failure log.
And if I had to compress the entire post into one build instruction, it would still be:
build the memory substrate first, then earn the right to add the assistant.
8. The Operational Layer
This is the part almost nobody includes in their “how I built my memory system” write-up, and it is the part most likely to decide whether the project survives.
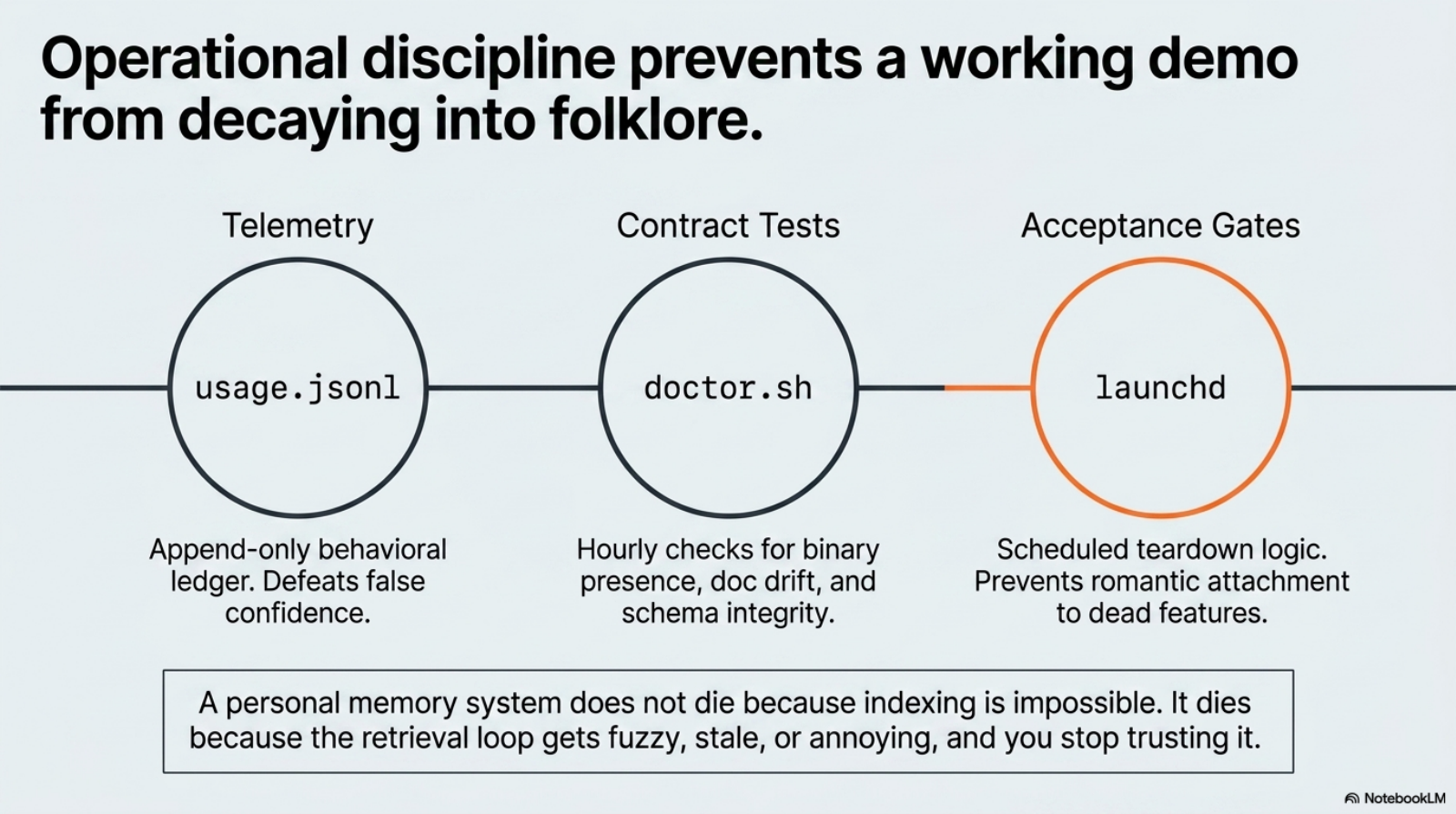
My operational layer has five pieces:
| Piece | Role | What it protects against |
|---|---|---|
usage.jsonl | append-only telemetry for invocations, surfaces, latency, and outcomes | false confidence from anecdotal success |
doctor.sh | hourly health checks for QMD, CLI health, JSONL integrity, tests, map drift | silent substrate or runtime decay |
| launchd jobs | keep checks and acceptance gates firing even when memory is not top of mind | ”I forgot to look, so the system drifted for a week” |
| test harness | verify input validation, timeout behavior, inbox sanitization, concurrency integrity | regression hiding behind plausible output |
| acceptance gate | decide whether the wedge deserves to live past Week 1 | hobby-project inertia and self-deception |
That last row matters. Monitoring is not enough. A system that only collects health data but never uses it to make continuation or teardown decisions still rots politically even if it is healthy technically.
8.1 Telemetry Is the Ground Truth of Use
usage.jsonl is the system’s behavioral ledger. Every meaningful user-facing or doctor-facing action appends a structured row under a file lock.
The schema is intentionally boring:
schematssurfaceevent- event-specific fields such as:
latency_msquery_lenn_hitswalk_msn_totalfailuresentry_idpath
The boringness is a feature. This file needs to survive shell tools, ad hoc parsing, and future schema evolution.
Three implementation choices matter more than they look:
| Choice | Why it exists |
|---|---|
| append-only JSONL | partial corruption is local to a line, not a whole database page |
schema: 1 on every row | future parsers can distinguish format drift from bad data |
fcntl.flock(LOCK_EX) around append | concurrent invocations do not interleave bytes and create torn writes |
That last property is tested directly. The test harness spins up concurrent inbox writes and verifies that the file contains the expected number of valid JSON rows, not half-records glued together.
The point of telemetry here is not “analytics.” It is operational truth. When I want to know whether the terminal surface or Claude Code surface actually got used, whether query latency stayed within budget, or whether doctor failures happened while I was not looking, this file is the ground truth.
8.2 The Doctor Is an Hourly Contract Test
The doctor script does not just check “is the binary there.” It checks whether the system is still the system.
Today it verifies, at minimum:
| Check | Why it matters |
|---|---|
qmd is on PATH | retrieval substrate still resolves from the runtime environment |
brain.py --version runs | the main entrypoint is executable and not obviously broken |
usage.jsonl parses line-by-line | torn writes and schema corruption are caught early |
usage.jsonl mode is 0o600 | raw queries and notes are not accidentally world-readable |
| wedge test suite passes | command contract regressions are surfaced within an hour |
MAP.md citations still resolve | docs and code did not silently drift apart |
| week-1 acceptance catch-up fires | the acceptance verdict still runs even if the laptop slept through the scheduled moment |
That is a stronger contract than generic “health checks.” It is not only availability. It is availability plus behavioral invariants plus documentation integrity.
The doctor is also explicitly written to keep going after the first failure. It does not set -e. That means one failure does not mask the others. If qmd is missing and the JSONL file is corrupt, I want both facts in the same pass.
And the output is not just local logging. On failure, the doctor:
- appends a
doctor_runtelemetry row with afailuresarray - writes a timestamped line to
/tmp/brain-doctor.log - fires a macOS notification so the failure becomes visible within the hour
This is what I mean by anti-rot architecture. The memory system is forced to keep proving that its docs, commands, and operational assumptions still match reality.
That gives the third law:
if your memory system cannot explain its own state, it will eventually lie to you.
8.3 Tests Guard the Wedge, Not the Dream
The test suite is deliberately wedge-specific. It is not trying to prove that “memory works” in the abstract. It is trying to prove that the user-facing contract fails in controlled ways.
The current test categories cover:
| Test category | Example invariant |
|---|---|
| query escaping | shell-dangerous input is rejected instead of passed through |
| frontmatter sanitization | inbox payloads cannot smuggle YAML that mutates the stored document |
| JSONL concurrency | simultaneous writes still produce valid telemetry |
| refusal guard | activity-log or code-reference style content can be refused or gated |
| structured exit codes | timeout, missing QMD, no-results, and bad-query states are machine-readable |
| schema integrity | emitted rows contain the required fields and secure file mode |
| explain surface | brain.py explain reports the sections and state the operator depends on |
This is a different posture from product demos. A demo asks, “can it retrieve something?” The wedge tests ask:
- can it reject a poisoned query?
- can it preserve telemetry under concurrency?
- can it fail with the right exit code?
- can it refuse unsafe capture?
- can it keep its explain surface truthful?
That is the boundary between an idea and a tool.
8.4 Exit Codes Are Part of the API
Human-readable stderr is not enough once agents or scripts start using the wedge. The runtime therefore treats exit codes as a first-class contract.
The current codes are:
| Exit code | Meaning | Operational use |
|---|---|---|
0 | success | command completed with usable output |
64 | bad query / bad input | caller should fix arguments, not retry blindly |
65 | QMD missing | substrate or environment issue |
66 | QMD timeout | caller can retry with a larger timeout or repair embeddings / index path |
67 | no results | absence is explicit, not conflated with failure |
70 | lock contention | shared-state write path is contested |
71 | refused / gated | policy refusal, not execution failure |
99 | internal error | unexpected runtime failure |
That separation matters because “no results” and “QMD timed out” are not the same operational event even if both would look like “nothing useful came back” in a naive chat surface.
The same principle shows up in JSON error payloads. For machine consumers, the runtime emits structured objects like:
error: qmd_timeouterror: qmd_missingerror: refused
with a fix hint where appropriate.
That means the harness is not only executing retrieval. It is shaping failure into something both humans and agents can route on.
8.5 The Scheduler Owns the Boring Reliability
launchd is not glamorous, but it is the reason the operational layer is not aspirational.
In this setup, schedulers own two kinds of work:
| Scheduled responsibility | Why it is scheduled instead of manual |
|---|---|
| hourly doctor passes | health only matters if it keeps running when I forget |
| week-1 acceptance check | the verdict must fire even if I do not remember the date |
There is an important detail here: the week-1 acceptance script is also called from doctor as a catch-up path. If the laptop is asleep when the scheduled acceptance time passes, the next doctor run still gives the verdict a chance to self-fire. That is not complexity for its own sake. It is resilience against the boring realities of an intermittently-on laptop.
This is the scheduler principle I keep coming back to:
any check that only works when I remember to run it is not part of the architecture yet.
8.6 Acceptance Gates Prevent Romantic Attachment
The final operational layer is not technical at all. It is decision discipline.
The Week-1 gate exists to answer questions that pure health checks cannot:
- did the three subcommands get used enough to matter?
- did latency stay within the budget?
- did the Claude Code surface actually earn its complexity?
- is this becoming habit, or am I manually propping it up because I want the project to be true?
That is why the plan includes explicit continuation, pivot, and teardown logic. If the usage pattern does not justify the wedge, the correct move is not “keep polishing.” The correct move is to shut down the experiment or change the surface.
There is a deep reason this belongs in the same section as telemetry and health checks. A memory system can be:
- technically healthy
- retrieval-correct
- operationally stable
and still not deserve to exist as a product surface.
Operational discipline, then, has two layers:
| Layer | Question |
|---|---|
| runtime health | is the system still behaving correctly? |
| product health | is the system earning continued attention through actual use? |
The deeper reason this matters is that memory systems are uniquely vulnerable to false confidence.
If a web app breaks, you see the broken page.
If a memory system breaks, you get something worse:
- incomplete recall that looks plausible
- stale documents treated as current truth
- silently skipped embeddings
- malformed telemetry that kills the evaluation loop
- prompt-injected source material quoted back as if it were trustworthy
That is why the runtime has structured exit codes, timeouts, flocked telemetry writes, and explicit error surfaces. This is not just tooling polish. It is part of the product contract.
9. Where This Breaks
Every memory system has failure modes. If it does not, it is either trivial or lying.

I find it more useful to classify the breaks by what kind of lie they produce.
9.1 Freshness Asymmetry
The first break is not “stale data” in the abstract. It is asymmetric freshness across layers.
In this system, lexical visibility and semantic visibility are different clocks:
qmd updatemakes new text searchableqmd embedmakes that text semantically retrievable
When those clocks diverge, the system can be fresh in one mode and stale in another. That is a worse failure than being uniformly stale because it is harder to notice.
Symptoms look like this:
| Symptom | Likely underlying break |
|---|---|
| literal query works, paraphrase query misses | embeddings are lagging behind lexical indexing |
recent session appears in qmd search, but not in semantic routes | vector layer is stale |
| one collection feels “invisible” in semantic recall | its embedding refresh path has stalled |
This is why I do not treat “the index is up to date” as a single boolean. It is at least two booleans:
- BM25 fresh?
- vectors fresh?
The live stack already shows why this matters. brain ask "qmd embed" --json returns quickly with hits from the raw brain layer, while recent collection status still shows freshness skew across collections. Fast answers can therefore coexist with uneven substrate freshness.
9.2 Temporal Lies
A memory hit is not live truth. It is a timestamped observation.
That sounds obvious until you see how easy it is for retrieval to erase time. Once a snippet is extracted and shown in a fresh terminal output, it psychologically feels current even if it came from a week-old session that is already obsolete.
This is why the runtime attaches:
- age labels such as
today,yesterday, orN days ago - freshness warnings only when the age passes the noise threshold
The failure mode here is not just stale data. It is stale data presented with fresh confidence.
Typical examples:
- a retrieved design note describes an architecture that has since changed
- a remembered command still appears valid even though the CLI flags drifted
- browser history suggests “recent interest” even though that collection has not ingested in days
Time metadata is therefore not decoration. It is part of truthfulness.
9.3 Untrusted Context
A memory corpus is full of text that did not originate as careful internal knowledge.
It includes:
- browser titles
- search queries
- pasted snippets
- external articles
- LLM-generated summaries
- malformed or manipulative source text
If you pipe that material into a larger agent loop without containment, the retrieval layer becomes a prompt-injection transport.
The system already defends one narrow slice of this problem on the write path:
- inbox frontmatter is sanitized
- certain derivable or policy-problematic captures are refused or gated
But retrieval-side trust is harder. A snippet can be perfectly well indexed and still be unsafe to obey. The correct posture is:
| Retrieved text type | Trust level |
|---|---|
| your own structured note | low-to-medium trust |
| raw session text | medium provenance, low semantic cleanliness |
| browser/page title | low trust |
| external article text | low trust unless re-verified |
| distilled summary | medium trust, but lossy |
The system can surface context. It cannot magically upgrade that context into truth.
9.4 Compression Drift
Distillation solves one problem by creating another.
It solves:
- transcript sprawl
- low-signal repetition
- hard-to-query verbosity
But it creates:
- summary bias
- concept flattening
- omission of rejected alternatives
- phrasing lock-in around the distiller’s wording
This is why I do not think raw and distilled layers are alternatives. They are adversaries. Each exists partly to keep the other honest.
The failure pattern is subtle:
| If you lean too hard on… | You get… |
|---|---|
| raw transcripts | high recall, high noise, poor conceptual compression |
| distilled artifacts | semantic clarity, but higher risk of over-smoothing or omission |
When the distillation layer drifts, retrieval starts converging on the same summary language repeatedly, even when the source material contained uncertainty or conflict. That is a semantic narrowing failure, not just a summarization flaw.
9.5 Surface Contamination
A memory layer can be healthy at the file level and still become unhealthy at the surface level.
I saw that directly in the recency audit. The last 24 hours of recent --json were heavy with benchmark and answer-eval style synthetic sessions in the brain collection. Those files are real. They belong in the corpus. But if they dominate the recency surface, the surface stops reflecting what I most need to remember.
This is a different class of failure from bad indexing. The documents are there. The retrieval engine works. The surface still becomes misleading because the wrong artifact class is winning the competition.
Surface contamination typically appears as:
- synthetic eval sessions crowding out normal work
- bulk-ingested external content overwhelming personal notes
- noisy browsing exhaust overwhelming stable project memory
This is why I audit not only correctness, but surface shape.
9.6 Operator Overfit
This system is optimized for a particular operator profile:
- terminal-native
- comfortable inspecting files directly
- willing to think in collections
- local-first
- comfortable with markdown and shell tools
- already using agents as collaborators
That is not a neutral baseline. It is a strong prior.
So even if the architecture is internally coherent, it may still fail for users who:
- want ambient capture over explicit capture
- prefer mobile-first interaction
- do not trust terminals
- do not want to manage corpus hygiene manually
This is the product-level version of overfitting. The system can be correct for me and still wrong as a general surface.
9.7 Retrieval Budget Pressure
The final break is economic, not conceptual.
Every layer I add makes some other layer harder:
- more capture increases normalization burden
- more documents increase candidate competition
- more semantic search increases embedding maintenance
- more surfaces increase telemetry and support burden
Retrieval quality does not degrade only because models are weak. It degrades because the budget gets fragmented:
| Resource under pressure | What degrades first |
|---|---|
| latency budget | interactive trust |
| corpus discipline | result quality |
| embedding freshness | semantic recall |
| operator attention | maintenance and debugging |
| surface clarity | adoption and habit formation |
This is why I do not think of “more capture” as progress unless it is paired with corpus discipline and eval discipline.
10. What This Architecture Buys
When this design works, it buys a specific kind of leverage that most second-brain products blur together.
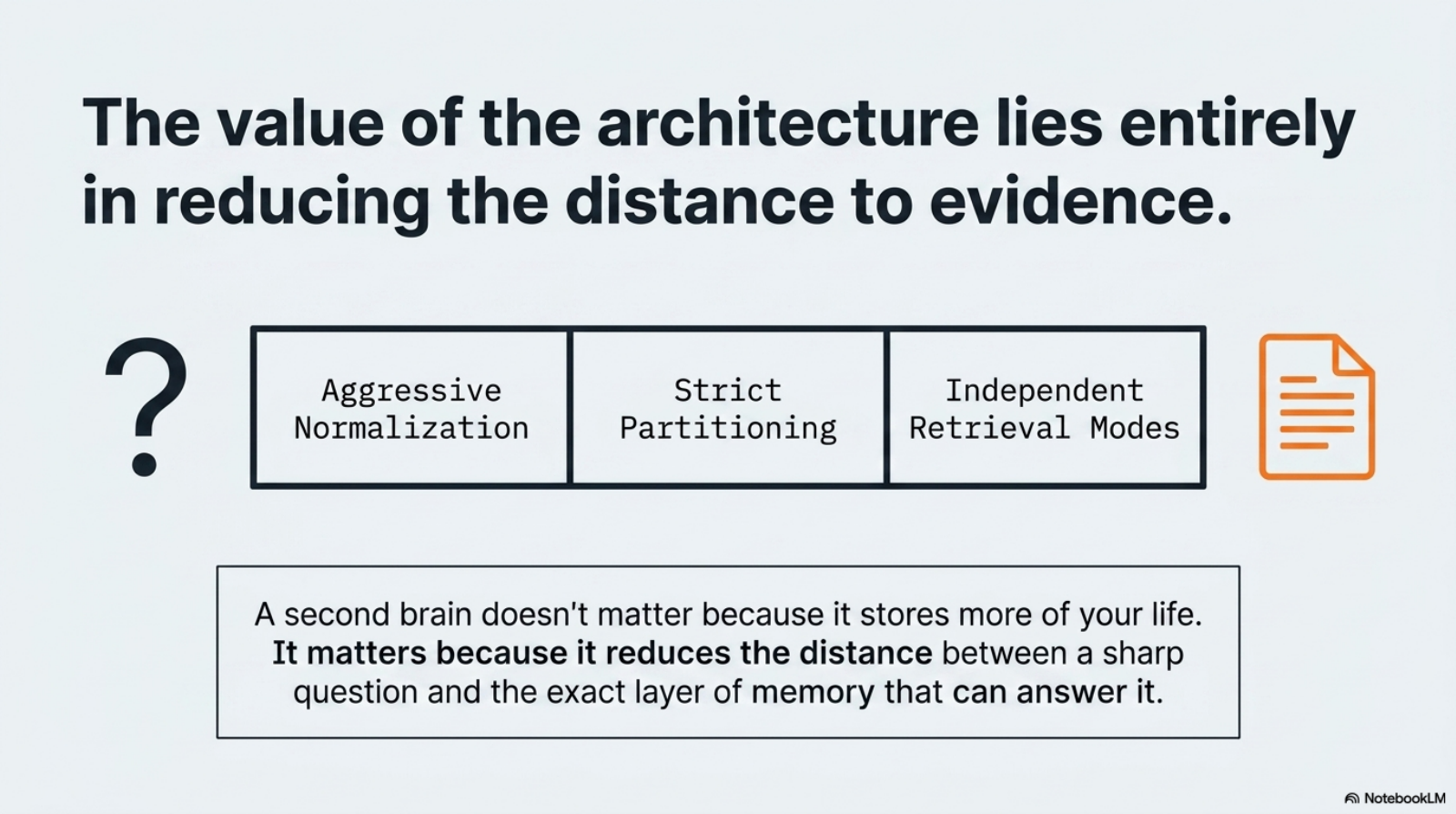
I would break that leverage into five payoffs:
| Payoff | What you get | What you avoid |
|---|---|---|
| locality | the corpus lives as files on disk, under your control | outsourced memory trapped behind a hosted product or opaque sync layer |
| inspectability | every layer can be read, grepped, diffed, and debugged with ordinary tools | black-box retrieval where failure analysis starts with guesswork |
| boundary clarity | QMD, MCP, CLI, scheduler, and skills each own a narrow contract | a single “smart assistant” surface that hides where failures actually live |
| retrieval discipline | different artifact classes compete in structured ways instead of one giant undifferentiated pool | semantic soup where everything is searchable but very little is reliably retrievable |
| agent readiness | the corpus is already shaped for both human recall and tool-mediated retrieval | bolting an agent on top of raw notes and hoping prompt engineering compensates |
Those payoffs are more operational than inspirational. This architecture does not buy me omniscience. It buys me a shorter path from question to evidence.
That is the core lesson I keep coming back to:
the value of a second brain is not that it stores more of your life. The value is that it reduces the distance between a question and the exact layer of memory that can answer it.
That distance is an architectural property.
It depends on:
- how artifacts are normalized
- how collections are split
- how freshness is maintained
- which retrieval modes are available
- how runtime policy shapes recall
- whether the surfaces remain narrow enough to trust
- and whether the system survives enough real use to keep its shape
I no longer think about this project as a “personal knowledge management app.” It is closer to a local retrieval operating system for my work.
That phrase is not branding. It is a statement about responsibility:
| If this were just an app… | But as a retrieval operating system… |
|---|---|
| the UI would be the product | the corpus and contracts are the product |
| one assistant surface would dominate | multiple surfaces can coexist over one substrate |
| debugging would stay inside the app | debugging can happen at the file, index, runtime, or skill layer |
| feature count would look like progress | only reduced recall distance counts as progress |
There is also a second-order benefit that matters more as agents become normal tooling: once the memory substrate is shaped correctly, you do not need to rebuild memory for every surface.
The same underlying corpus can support:
- terminal recall
- Claude Code skills
- MCP-mediated retrieval
- future briefings or summarization layers
- evaluation harnesses over the memory stack itself
That reuse only works because the substrate is stable and inspectable. If the memory system is just “whatever the current chat product happened to store,” each new surface starts from zero.
10.1 What It Does Not Buy
This architecture also refuses to buy a few fantasies:
| Fantasy | Why this stack does not promise it |
|---|---|
| perfect memory | ingestion is selective, distillation is lossy, and freshness is uneven |
| live truth | retrieval returns timestamped observations, not guaranteed current state |
| automatic judgment | search can surface context, but it cannot decide what should matter |
| universal product fit | the operator model here is specific and opinionated |
| free complexity | every new source, surface, or retrieval mode increases maintenance burden |
That refusal matters because it keeps the architecture honest. The system should be judged against the job it actually does: making certain classes of recall cheap, inspectable, and repeatable.
If you want to build one, I would start with a narrower goal than “remember everything.” I would start with a sharper question:
What exact classes of recall do you want to make cheap?
Then build backward from that:
- define the artifact classes
- define the document boundaries
- normalize aggressively
- split the collections by retrieval role
- make lexical retrieval work before semantic retrieval
- keep the harness thin
- make the skills explicit
- instrument the failure paths
- measure whether recall is actually getting cheaper
This is the real standard:
| Weak standard | Strong standard |
|---|---|
| ”does the system know a lot?" | "does the right layer answer a sharp question quickly enough to change my behavior?" |
| "can it generate a clever answer?" | "will I trust it enough to ask again tomorrow?" |
| "did I capture more data?" | "did recall distance go down?” |
The system does not become a second brain when you capture enough.
It becomes one when recall becomes a reliable habit.
That is the standard I care about now. Not “does the system know a lot?” Not “can it generate a clever answer?” The standard is harsher:
when I ask my own history a sharp question, does the right layer answer quickly enough that I will ask again tomorrow?
This post builds on two earlier essays: The 14K Token Debt and The Terminal Was the First Agent Harness. Those argued that prompts and terminals are architectural surfaces. This is the memory layer that sits underneath them.