81.6% on LongMemEval

Brain scored 408/500 = 81.60% on LongMemEval_s — matching Supermemory’s GPT-4o row, using only BM25 retrieval and a Claude Sonnet reader, on a stack that runs locally.
The result has a sharp boundary: my judge was Sonnet, not GPT-4o, so this is not a strict leaderboard replacement. But end-to-end it is a clean, full 500-question run with zero reader errors and zero judge errors. That is the number I trust.
| Metric | Result |
|---|---|
| Dataset | LongMemEval_s cleaned |
| Questions | 500/500 |
| Retriever | inproc-bm25, top-k=5 |
| Reader | claude-cli, claude-sonnet-4-6 |
| Judge | claude-sonnet-4-6 using the vendored official yes/no templates |
| Reader errors | 0 |
| Judge errors | 0 |
| QA accuracy | 408/500 = 81.60% |
| Retrieval recall@5 | 91.55% over 470 non-abstention questions |
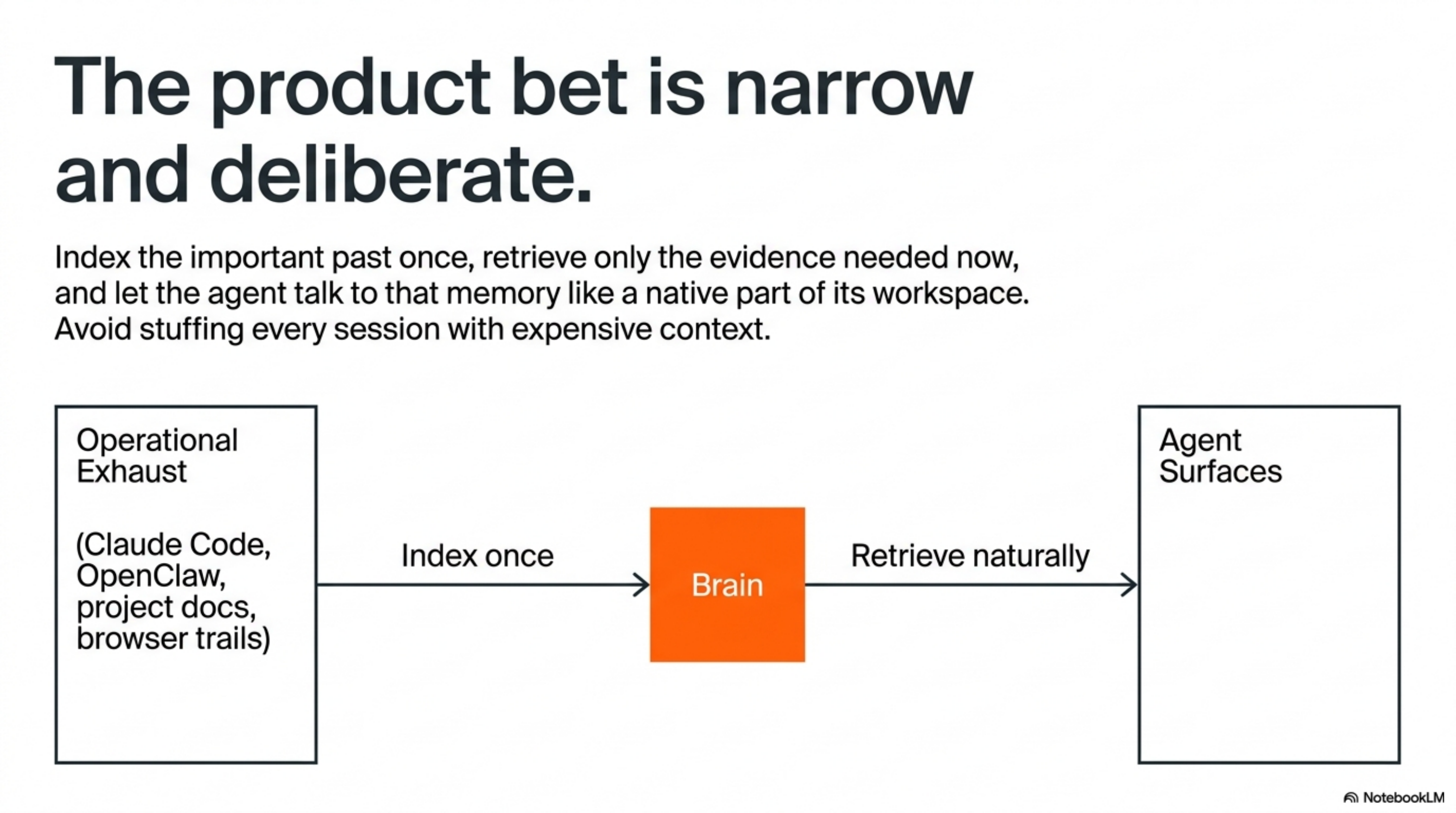
Brain is a product bet, not a chat UI. It indexes the important data around my work once — Claude Code sessions, OpenClaw runs, Hermes conversations, project docs, browser trails, notes, decisions, failures, the operational exhaust that usually disappears — and lets any agent surface ask that memory naturally: what did we decide about the auth flow?, where did this error happen before?, which benchmark run was clean?, what did I already try and reject?
The bet is narrower than “stuff every session with context”:
Index the important past once, retrieve only the evidence needed now, and let the agent talk to that memory like a native part of its workspace.
If Brain is going to sit behind Claude Code, OpenClaw, and Hermes as the memory layer, it cannot just feel useful. It has to answer held-out questions from long histories, recover the right evidence cheaply, and fail in ways I can inspect. Memory benchmarks are especially easy to overstate — a retrieval score can look like an answer score, a small sample can look like a full benchmark, a rate-limited run can leave half the dataset silently broken, a judge can be changed just enough to make the number prettier.
I benchmarked Brain because “it feels useful” is not enough to build a great product.
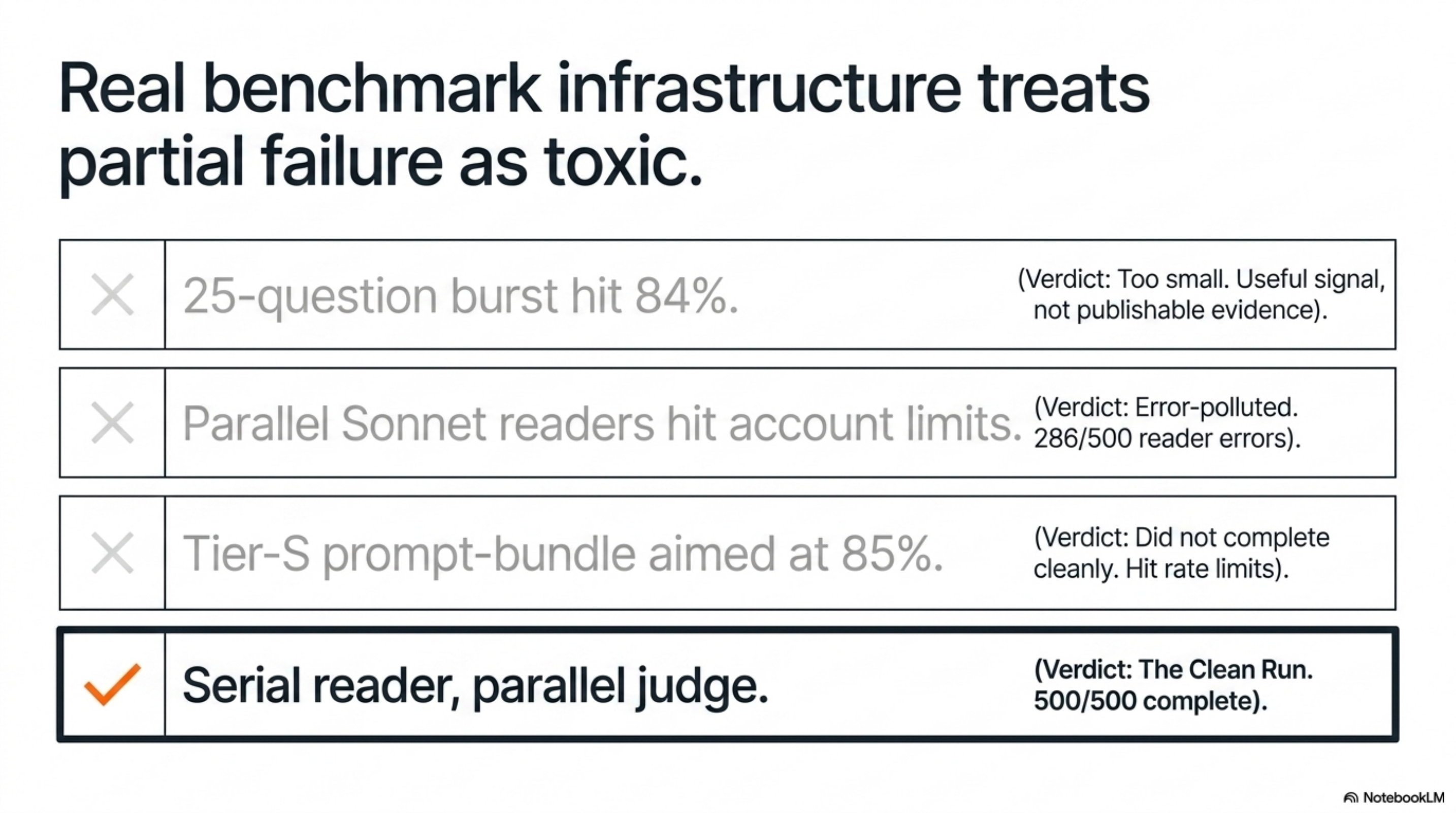
The rule I took from the whole exercise is the Clean Number Rule: if the run is partial, rate-limited, re-judged inconsistently, or silently missing questions, it is not a score — it is a debugging artifact.

The journey had four distinct phases:
| Phase | What happened | What survived |
|---|---|---|
| Harness build | Built bench/longmemeval/, dataset fetch, ingestion, retrieval, reader, judge wrappers | A repeatable benchmark loop instead of a demo |
| First Sonnet signal | A 25-question burst hit 84% | Useful signal, not publishable evidence |
| Failed full run | Parallel Sonnet readers hit account limits and left 286/500 reader errors | A hard rule: no error-polluted scores |
| Clean full run | Retried failed qids serially, re-judged all 500 | 408/500 = 81.60%, 0 reader errors, 0 judge errors |
That last row is the only one I am willing to call the benchmark result.
The story is not “we got a benchmark score.” The story is that a local memory layer can become product infrastructure only after it learns to prove what it remembers.
Why LongMemEval
Most memory systems are evaluated with questions that are too clean. A fact is inserted. A question asks for the fact. Retrieval finds the fact. The demo works.
Real agent memory is messier than that. The hard cases are not just “what was the user’s dog’s name?” They are:
- facts scattered across sessions
- old information overwritten by newer information
- timestamps that change the answer
- assistant-side statements that matter later
- preference questions where the evidence is implicit
- abstention questions where the right behavior is to say there is not enough information
That is why I used LongMemEval. The benchmark was built for long-term interactive memory, not generic RAG. The LongMemEval GitHub repository describes 500 questions covering information extraction, multi-session reasoning, knowledge updates, temporal reasoning, and abstention, and links the cleaned data on Hugging Face. The underlying paper is LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory.
The small variant, LongMemEval_s, gives each question roughly 115k tokens of chat history across about 40 sessions; the medium variant pushes toward 500 sessions.
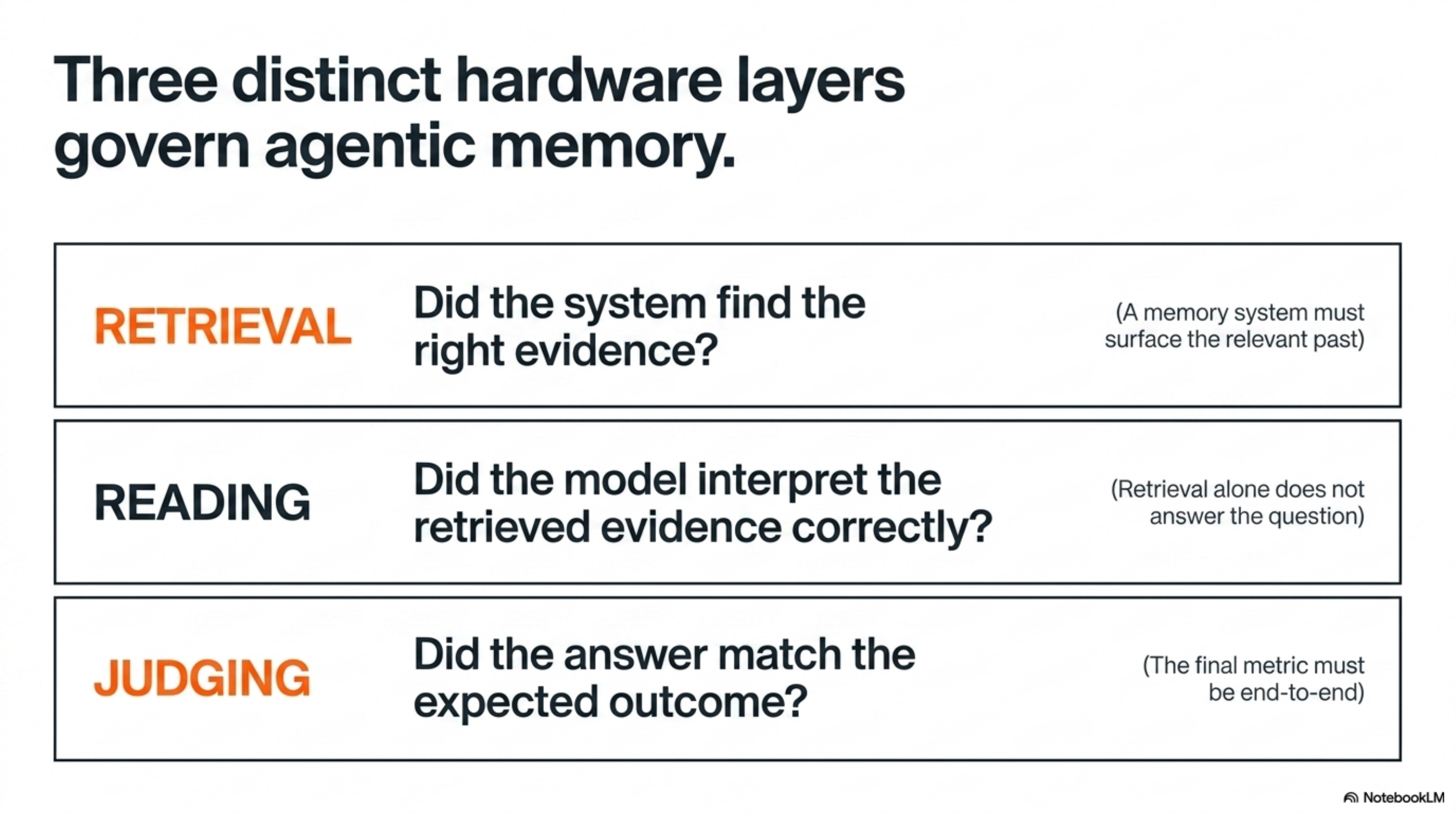
That shape matters. It separates three things people often collapse into one:
| Layer | Question it answers | Why it matters |
|---|---|---|
| Retrieval | Did the system find the right evidence? | A memory system must surface the relevant past. |
| Reading | Did the model interpret the retrieved evidence correctly? | Retrieval alone does not answer the question. |
| Judging | Did the answer match the expected answer? | The final metric has to be end-to-end. |
The LongMemEval authors also make a point that matched my own experience: even with strong long-context models, long-term memory still needs explicit machinery. The benchmark is not just asking whether a model has a long context window. It is asking whether the system can manage a growing interaction history.
That is exactly the claim Brain has to survive: not “can we stuff all history into context?”, but “can a retrieval substrate make the right past available to the right agent at the right moment without paying a huge token and latency tax?”
The Product Claim
Brain started as my local-first memory layer for Claude Code and related agent work, but the product shape is broader than one assistant.
At the time of the earlier production writeup, the system was already indexing hundreds of Claude Code sessions into markdown, distilling high-signal summaries, and exposing retrieval through QMD and MCP. The goal was to make memory feel native across agent surfaces: important data flows into a normalized markdown corpus, gets indexed lexically and semantically (lexical / vector / HyDE), and exposes itself as brain ask / brain recent / MCP — so Claude Code, OpenClaw, and Hermes can ask natural questions against the user’s past.
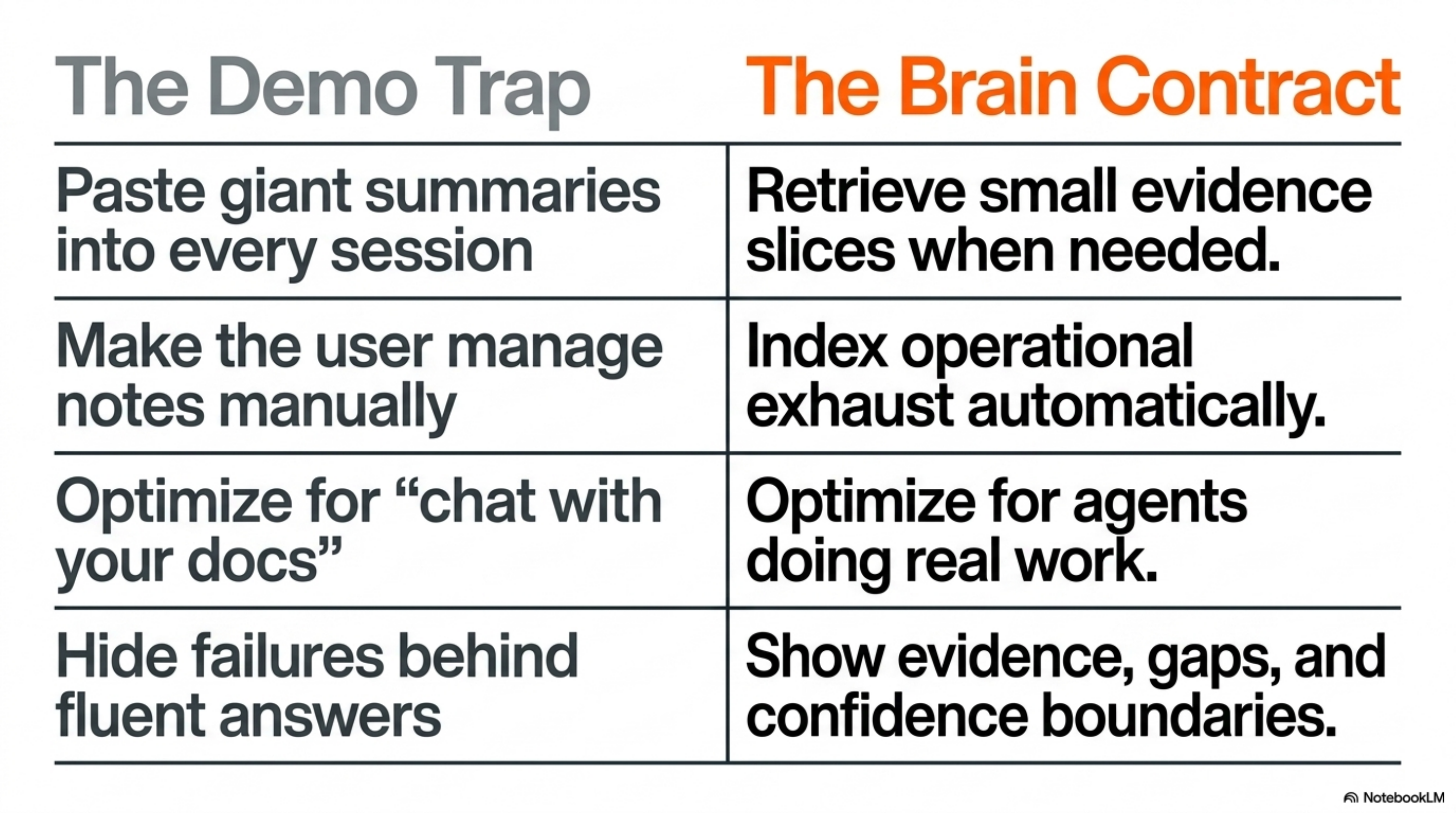
This is the key product distinction:
| Bad memory product | Brain product goal |
|---|---|
| Paste giant summaries into every session | Retrieve small evidence slices when needed |
| Make the user manage notes manually | Index operational exhaust automatically |
| Optimize for “chat with your docs” demos | Optimize for agents doing real work |
| Hide failures behind fluent answers | Show evidence, gaps, and confidence boundaries |
| Spend more tokens to feel safer | Spend fewer tokens by retrieving better |
The system helped me every day. It could remember decisions, commands, failures, review comments, abandoned approaches, and “we already tried that” context. But daily usefulness creates a trap. If a memory system helps you personally, you start trusting it before you have measured it.
That is dangerous because memory failures often look plausible. The agent gives an answer with confidence, but the missing evidence is invisible. For a product, that is the failure mode that matters: not forgetting loudly, but remembering wrongly while sounding useful.
So I needed an external test with enough structure to make failure legible.
I call this the Harness Before Hype rule:
| Temptation | Better discipline |
|---|---|
| Publish an architecture diagram | First publish the metric it survives. |
| Report retrieval recall | Also report end-to-end QA. |
| Show the best examples | Score all 500 questions. |
| Optimize the prompt live | Keep the judge template fixed. |
| Round the number up | Preserve the clean run exactly. |
That rule shaped the whole LongMemEval project, but the product reason was simple: if Brain is going to save tokens and time for real agent work, I need to know what quality I am buying with that cheap retrieval path.
The benchmark also made Brain more legible as a product. Before LongMemEval, Brain was a useful local memory layer. After LongMemEval, it had a measurable contract:
| Claim | Measurement needed |
|---|---|
| Brain remembers prior work | End-to-end QA on held-out questions |
| Retrieval is good | Recall@k against evidence sessions |
| The reader is good | QA accuracy given retrieved sessions |
| The system is robust | 500/500 complete, no reader or judge errors |
| The result is comparable | Fixed dataset, fixed judge templates, named models |
That contract is what turns “memory” from a feature into infrastructure.
The Harness
I built bench/longmemeval/ as a normal benchmark harness, not a one-off notebook.
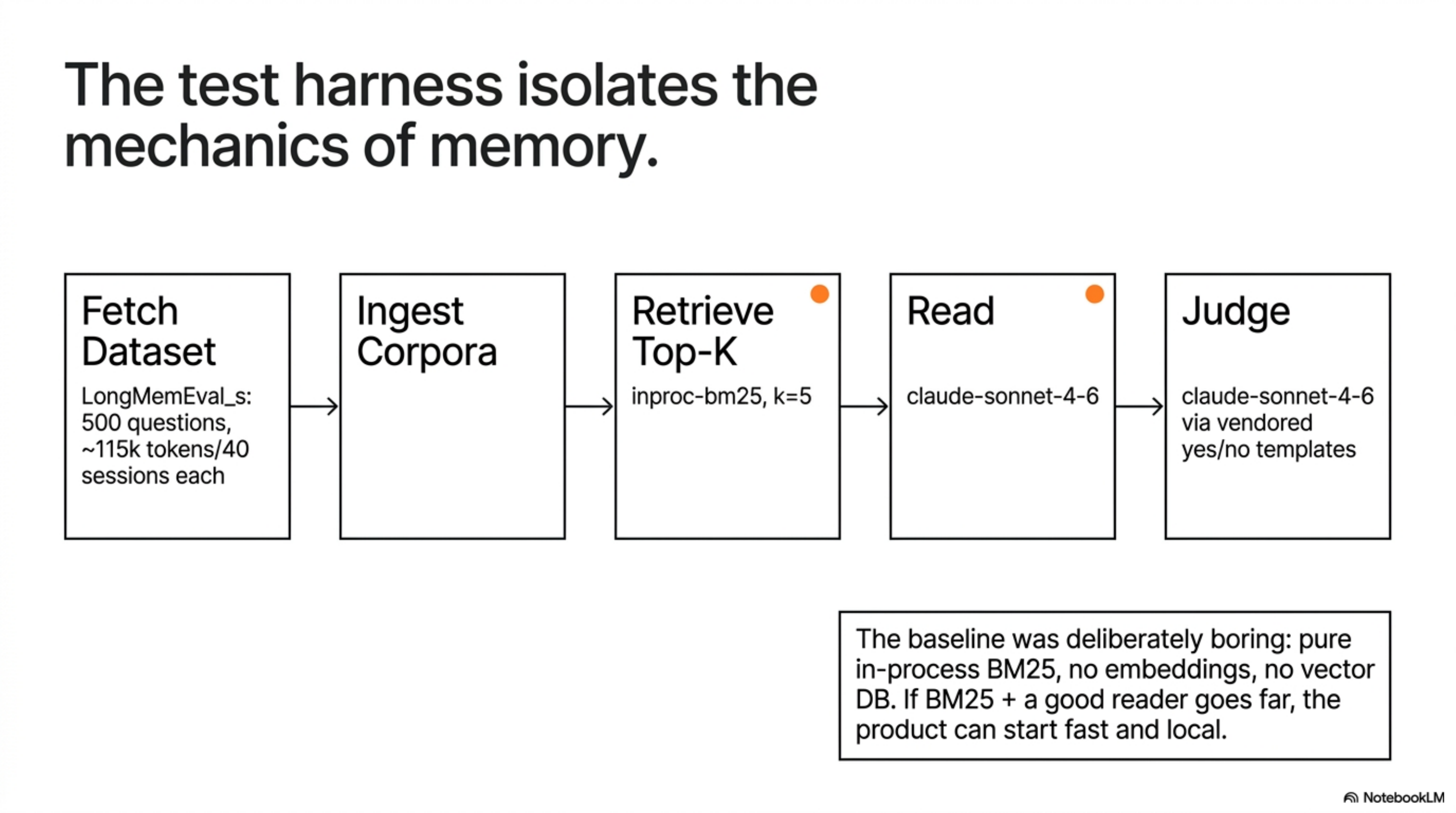
The pipeline had five stages: fetch the dataset, ingest per-question corpora, retrieve the top-k evidence sessions, ask a reader model for the answer, and judge that answer with LongMemEval-style yes/no templates.
The first committed baseline was deliberately boring: pure in-process BM25, no embeddings, no external vector DB, no custom memory graph.
That was the point. Before testing the full Brain stack, I wanted the cheapest credible product baseline: if BM25 plus a good reader already goes far, then the product can start fast and local instead of defaulting to expensive context stuffing.
The critical command shape looked like this:
python3 -m bench.longmemeval.run \
--variant s \
--retriever inproc-bm25 \
--reader claude-cli \
--tag fleet-0 \
-k 5 \
--qid-file bench/longmemeval/batches/batch_0.txtThe reader path used claude -p through the local Claude Code subscription: BM25 retrieves five sessions, Sonnet reads the question plus those retrieved sessions and emits one hypothesis, then the judge labels that hypothesis true or false.
The judge path used the same official yes/no templates vendored from LongMemEval’s evaluate_qa.py, routed through Claude instead of GPT-4o.
That last sentence is important. This was a clean internal run, but not a perfect apples-to-apples public leaderboard submission. The LongMemEval repository documents GPT-4o-based evaluation. My run used Sonnet as both reader and judge because it let me run the full system without API spend.
So the precise claim is:
Brain’s BM25 + Sonnet run scored 81.60% under a Sonnet implementation of the official LongMemEval yes/no judge templates.
It is a real end-to-end score. It is not the same thing as a GPT-4o-judged leaderboard entry.
The harness became a small contract: same 500 questions, same cleaned dataset, same retrieval k, same reader model, same judge templates, same aggregation script, no silent errors.
That contract matters more than any single prompt tweak.
The contract looked solid. Then the first serious run broke it, which is exactly why the harness mattered.
The Run That Failed
The first full attempt did not give me the final number.
It gave me lessons.
The early signal was promising: a 25-question burst hit 84%. That was useful, but it was not enough evidence to publish. A 25-question sample can be lucky, skewed by category, or easier than the full distribution.
Then I tried to scale the reader fleet in parallel. That was a mistake. Five parallel Sonnet readers tripped the weekly Claude limit and left the run with 286/500 reader errors.
At that point the harness had already taught me something more valuable than a score: benchmark infrastructure needs to treat partial failure as toxic.
I made three changes:
| Problem | Fix |
|---|---|
| Reader and retrieval errors were too entangled | Split retrieval and reader try-blocks so failures were tagged correctly. |
| Long runs were fragile | Added resume support and qid-file batches. |
| Rate limits polluted outputs | Added a circuit breaker after repeated rate-limit errors. |
The operational rule became:
Serial reader, parallel judge.
Readers are expensive, stateful, and easy to rate-limit. Judges are cheaper to resume and easier to shard. Once I separated those clocks, the full run became stable.
That was the unglamorous work that made the final number publishable.
This is also where Claude Code hooks became part of the broader Brain product story. Hooks are how everyday sessions enter the memory system automatically. The benchmark harness is the mirror image: instead of automatically capturing my work, it automatically forces the memory system to prove it can recover evidence later.
After that failure, the benchmark became simpler and stricter: finish all 500 questions, retry failures serially, judge everything cleanly, and only then look at the score.
The Run That Counted

The clean run completed all 500 questions with zero reader errors and zero judge errors.
The result surprised me in two opposite ways.
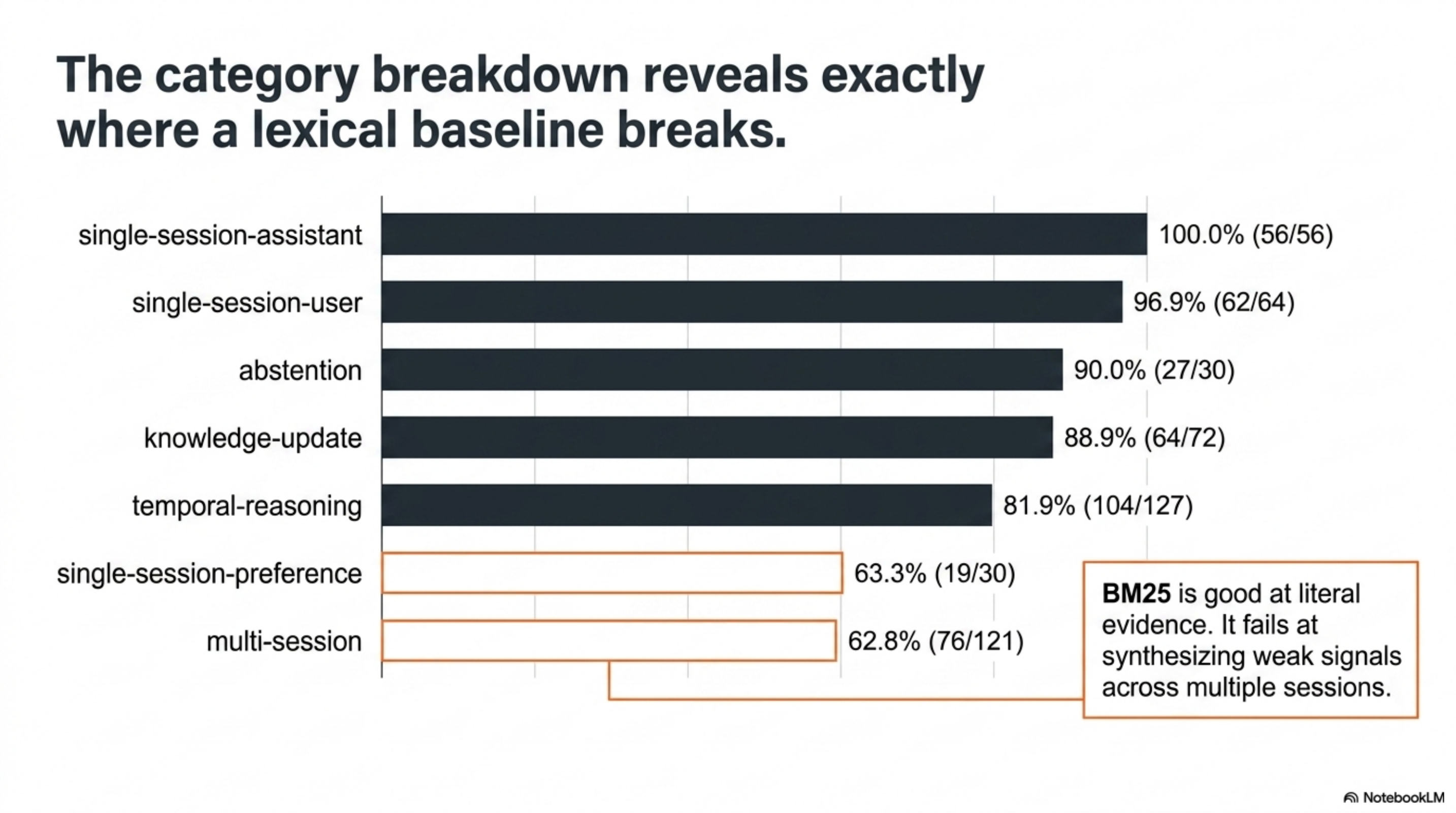
First, the simple baseline was much stronger than I expected. Plain BM25 plus Sonnet was enough to land in the same aggregate range as serious memory systems. Supermemory’s research page reports an 81.6% LongMemEval_s result for its GPT-4o row, with higher rows for stronger readers. My run matched that 81.6% aggregate number, while using a much simpler retrieval stack.
Second, the breakdown made the weakness obvious. Brain was excellent at direct single-session recall and strong on knowledge updates. It was weak on preference and multi-session reasoning.
That is exactly the failure pattern I would expect from BM25.
BM25 is good at literal evidence. It is less good when the answer requires synthesizing weak signals across multiple sessions or inferring a preference from repeated behavior. Those are not just retrieval problems. They are representation and reasoning problems.
The retrieval metric tells the same story. Recall@5 was 91.55%, but QA was 81.60%. That gap is the reader/judge split in action:
| Metric | Meaning | Result |
|---|---|---|
| recall@5 | Did the evidence session appear in the top 5? | 91.55% |
| QA accuracy | Did the final answer pass the judge? | 81.60% |
| gap | Evidence found but not converted into a correct answer | 9.95 points |
This is why I do not like memory claims that only report retrieval recall. Retrieval is necessary. It is not sufficient.
I think about this as the Evidence Conversion Gap — recall@k − QA accuracy, or 91.55 − 81.60 = 9.95 points.
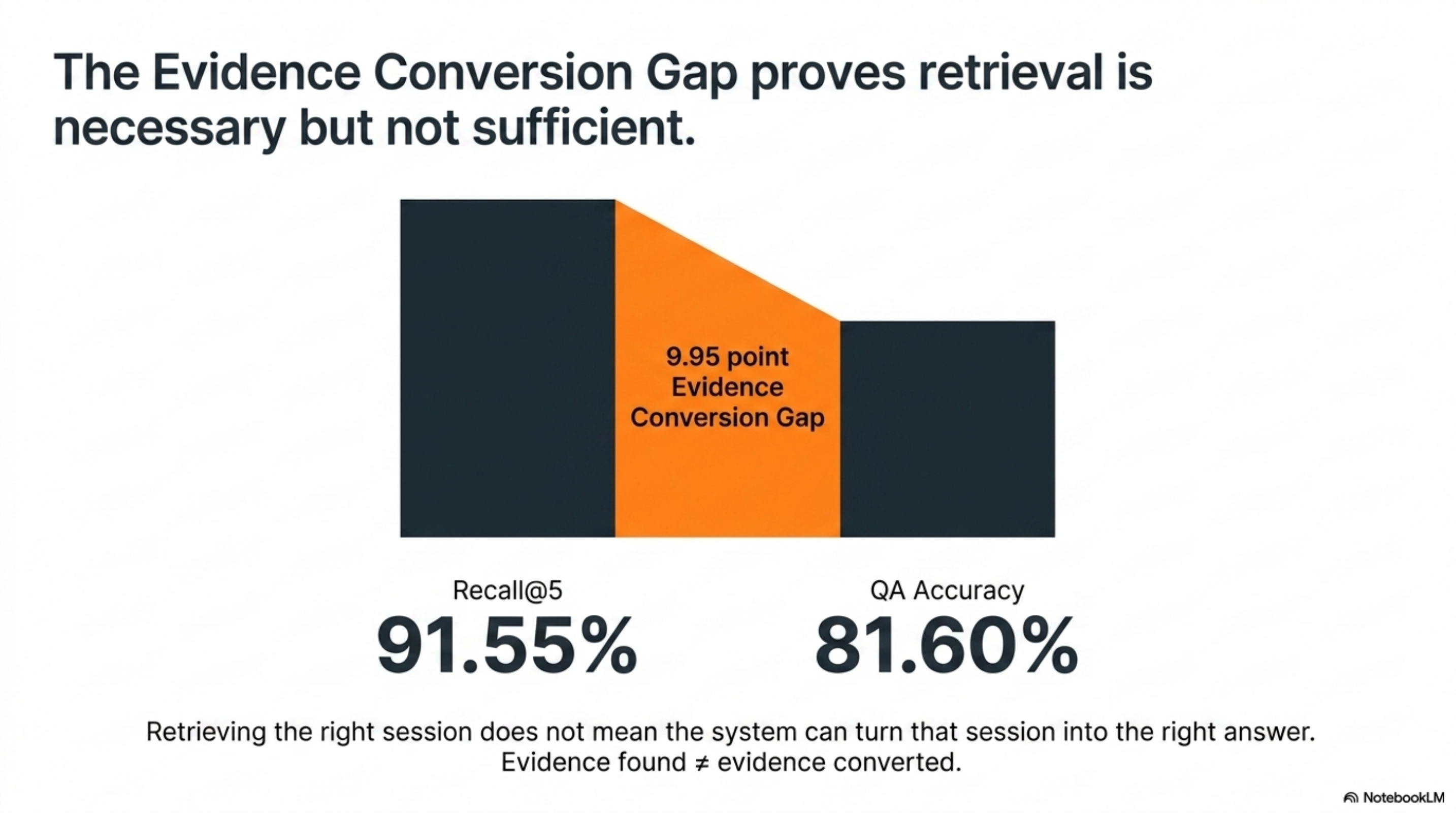
That gap is where the next product work lives. A memory system that retrieves the right session but cannot turn that session into the right answer has not solved agent memory. It has solved evidence surfacing.
So the aggregate said Brain was credible. The category breakdown said exactly where it was still weak. The next question was how that shape compared with a public memory system.
Where Brain Lands In The Public Field
LongMemEval does not have a single official leaderboard maintained by the benchmark authors. The public results are mostly vendor self-reports: research pages, leaderboard posts, press releases, and GitHub snippets. The fairest reading is “best public claims I could verify,” not a tournament with one referee.
In decreasing order of verified accuracy, the field looks like this:
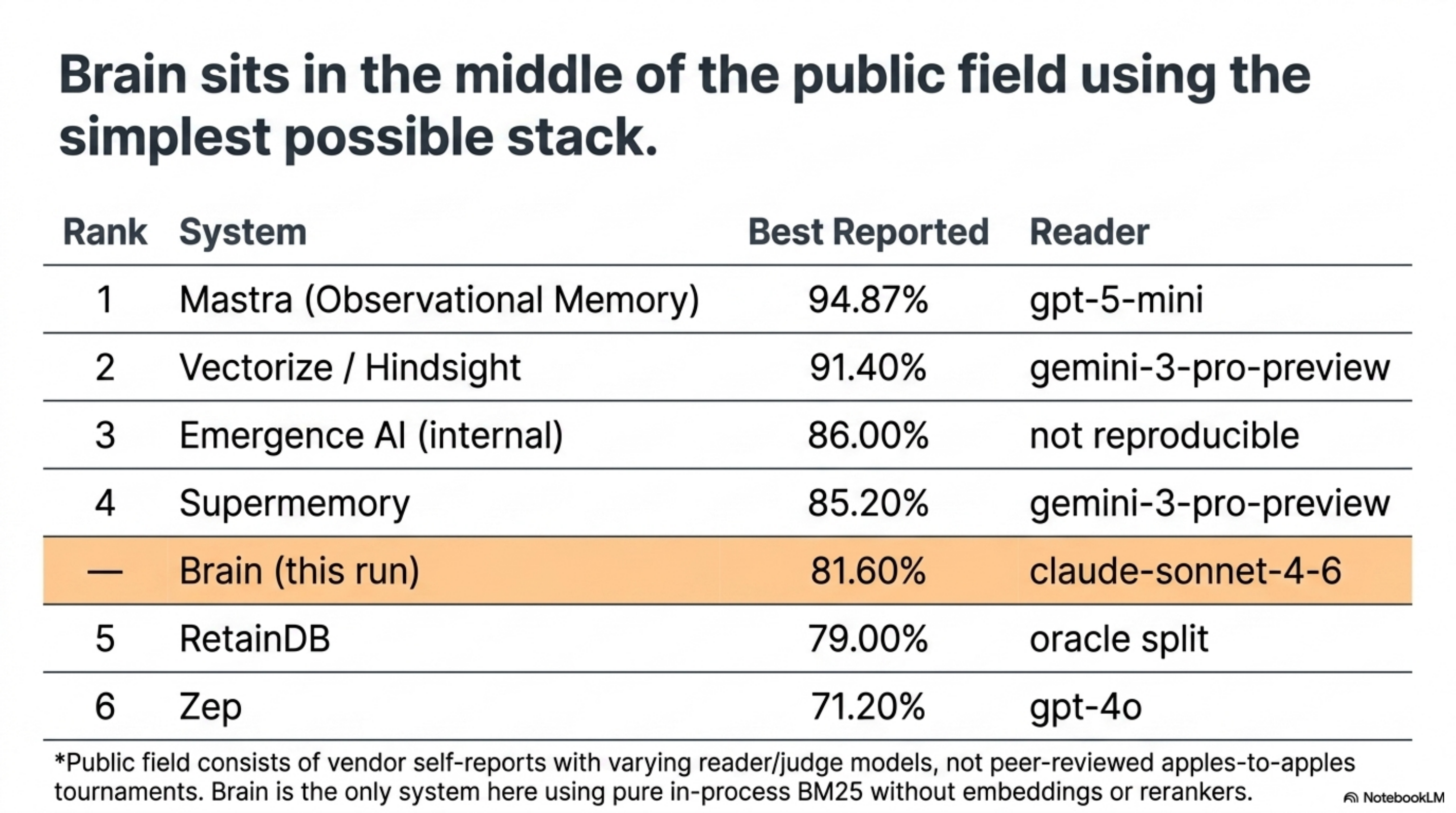
| Rank | System | Best reported | Reader | Source |
|---|---|---|---|---|
| 1 | Mastra (Observational Memory) | 94.87% | gpt-5-mini | mastra.ai/research |
| 2 | Vectorize / Hindsight | 91.40% | gemini-3-pro-preview | Mastra leaderboard |
| 3 | Emergence AI (internal) | 86.00% | not publicly reproducible | Mastra leaderboard |
| 4 | Supermemory | 85.20% | gemini-3-pro-preview | Mastra leaderboard |
| — | Brain (this run) | 81.60% | claude-sonnet-4-6 | bench/longmemeval/ |
| 5 | RetainDB | 79.00% | oracle split | arXiv 2410.10813 |
| 6 | Zep | 71.20% | gpt-4o | Mastra leaderboard |
Lighter-weight claims sit outside that list until methodology is checked side by side: Ensue AI’s 93.2% LinkedIn post and Backboard’s 93.4% GitHub snippet are real numbers but not yet apples-to-apples. Vectorize’s 91.4% was corroborated with The Washington Post and Virginia Tech partners; most of the other rows are single-source.
Two things matter about where Brain lands.
The first is that 81.60% sits in the middle of the public field while running the simplest possible stack: in-process BM25, top-k=5, no embeddings, no graph, no rerankers. Every system above Brain on this table runs richer memory machinery, a stronger reader, or both. Sitting in that band on a BM25 baseline is a stronger product signal than the rank itself.
The second is that this is not an apples-to-apples ranking. Reader models differ across rows. Judge models differ — most public numbers were judged by GPT-4o; Brain was judged by Sonnet. Some entries are internal configurations the authors say are not reproducible. Some are leaderboard rows; others are press or social posts. Treating this as a tournament would be sloppy.
LongMemEval itself was created by Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu, and the benchmark was accepted at ICLR 2025. Among the public results that exist today, the benchmarking activity is dominated by startups and product teams rather than named individual evaluators or standalone university labs. That is worth flagging because it shapes what “the field” is: a vendor scoreboard, not a peer-reviewed ranking.
The most useful per-system comparison is still Supermemory, because their research page breaks results out by category. That is the one place Brain can be matched on shape, not just aggregate:
| System row | Overall |
|---|---|
| Full-context (gpt-4o) | 60.2% |
| Zep (gpt-4o) | 71.2% |
| Supermemory (gpt-4o) | 81.6% |
| Supermemory (gpt-5) | 84.6% |
| Supermemory (gemini-3-pro) | 85.2% |
Brain’s clean Sonnet run tied the 81.6% aggregate reported for Supermemory’s GPT-4o row. It did not beat Supermemory’s higher-reader rows, and because my judge was Sonnet rather than GPT-4o, I would not present this as a strict leaderboard replacement.
The category shape comparison:
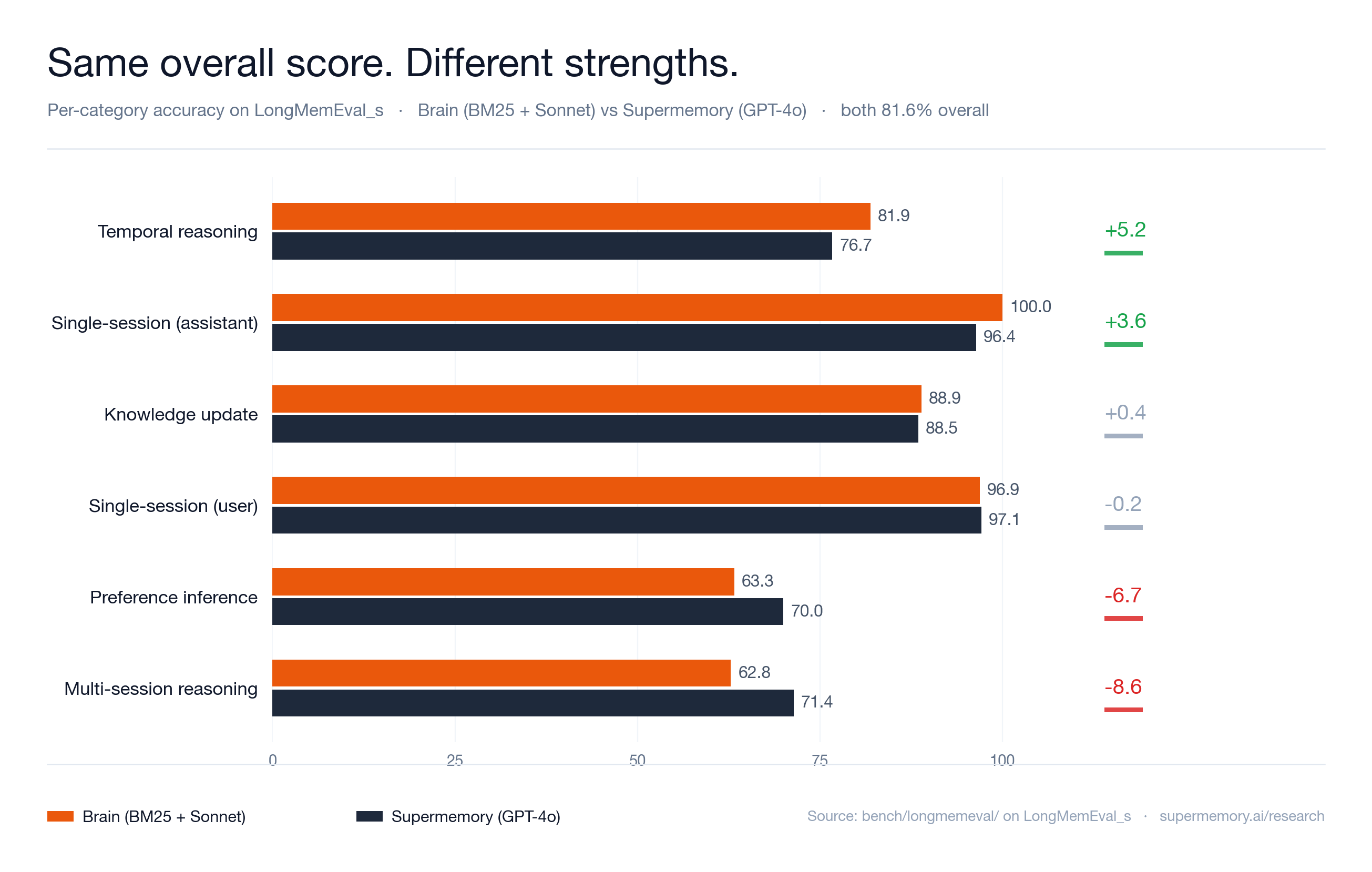

| Type | Brain | Supermemory gpt-4o row | Delta |
|---|---|---|---|
| single-session-user | 96.88 | 97.14 | -0.26 |
| single-session-assistant | 100.00 | 96.43 | +3.57 |
| single-session-preference | 63.33 | 70.00 | -6.67 |
| knowledge-update | 88.89 | 88.46 | +0.43 |
| temporal-reasoning | 81.89 | 76.69 | +5.20 |
| multi-session | 62.81 | 71.43 | -8.62 |
This is a much more useful pair than either aggregate.
It says Brain’s plain baseline is already competitive on direct recall, assistant-side recall, knowledge updates, and temporal reasoning. It also says the system is not yet good enough at cross-session synthesis or implicit preference modeling.
That is a product roadmap hiding inside a benchmark table.
I would not use this comparison or the broader leaderboard to claim “Brain beats Supermemory” or “Brain is fifth on the leaderboard.” Both framings would be sloppy. The stronger claim is narrower and more useful:
A local-first Brain baseline, using only BM25 and Sonnet, sits in the middle band of the public LongMemEval field — and exposes a clear multi-session weakness to fix next, before the more sophisticated parts of the Brain stack are even turned on.
That narrow claim is the point of the post. It is strong enough to matter, but constrained enough to be defensible.
Why This Was Not An 85% Post
There was an 85% target.
There was an 84% small-sample burst.
There was a Tier-S prompt-bundle run designed to test whether better answer discipline could push the system toward 85% or beyond.
But I did not find a completed clean 85% Sonnet run.
The Tier-S run was a good hypothesis, not a publishable result. It reached a partial state and then hit rate-limit failure. Publishing that as “Brain got 85%” would violate the reason I built the harness in the first place.
Here is the standard I am using:
| Evidence | Publishable? | Why |
|---|---|---|
| 25-question burst at 84% | No | Too small. Useful signal only. |
| Full run with 286 reader errors | No | Error-polluted. |
| Partial Tier-S run aimed at 85% | No | Did not complete cleanly. |
| Full 500-question run, 0 reader errors, 0 judge errors, 408/500 | Yes | Complete, reproducible, auditable. |
The clean number is 81.60%.
I would rather publish the lower number than train myself to trust a flattering one.
Where This Breaks
The result is strong enough to matter, but it has sharp boundaries.
| Limitation | Why it matters | What I would do before making a stronger claim |
|---|---|---|
| Sonnet judged Sonnet | Same-model reader/judge can share blind spots | Re-judge the 500 hypotheses with GPT-4o using the official LongMemEval path |
| BM25 was the headline retriever | It is a lexical baseline, not the full Brain stack | Run QMD hybrid retrieval with lex/vec/HyDE and compare per-category lift |
| LongMemEval_s only | The medium variant is closer to a heavier long-history workload | Repeat on LongMemEval_m after the harness is stable |
| No cost/latency table yet | A memory product has to be useful under real operating budgets | Add wall-clock, token, and cost estimates per question |
| Multi-session remained weak | The system finds evidence better than it synthesizes across sessions | Add a two-pass evidence table reader for multi-session questions |
| Public field is heterogeneous | Reader and judge models differ across vendor reports, so “rank” hides methodology spread | Re-judge against the official GPT-4o path before claiming a strict position; until then, frame the result as a band, not a place |
This is why I am framing 81.60% as a credible baseline, not an end-state victory.
Those limits do not weaken the result. They make the next experiment obvious.
What I Learned
The first lesson is that a memory benchmark is mostly a systems benchmark.
The actual QA line is short. The hard parts are resumption, error tagging, batch boundaries, judge reproducibility, output hygiene, and preventing a partial run from masquerading as a score.
The second lesson is that retrieval recall is an upper-bound hint, not the outcome. Brain found the right evidence far more often than it answered correctly. That means the next improvements should not only be “better search.” They should improve how evidence is structured for the reader.
The third lesson is that multi-session questions are the real test.
Single-session recall is table stakes. The important behavior is synthesis — session A says one thing, session B updates it, session C implies a preference, session D gives the timestamp, and the question asks for the current answer.
BM25 can surface pieces of that chain. It does not naturally build the chain.
That points to the next architecture:
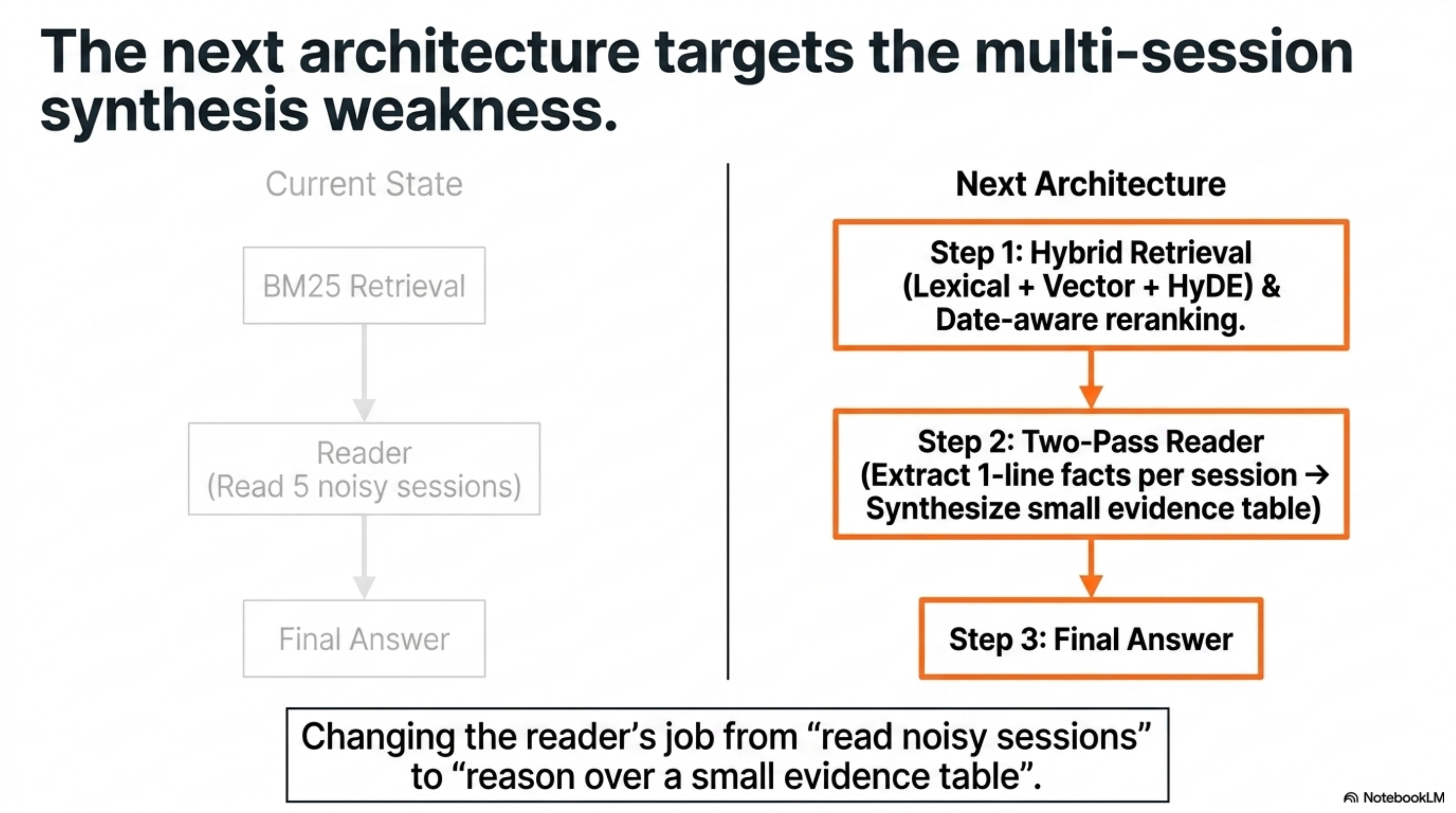
| Lever | Expected role |
|---|---|
| Hybrid retrieval | Improve semantic recall where BM25 misses vocabulary. |
| Date-aware reranking | Improve temporal questions by respecting event and session time. |
| Multi-session two-pass reader | Summarize evidence per session before synthesis. |
| Stronger independent judge | Reduce same-model reader/judge bias. |
| GPT-4o re-judge | Make the public number more comparable to published LongMemEval rows. |
Hybrid retrieval is the obvious next retrieval lever because QMD already exposes lexical, vector, and HyDE query modes. But the category table says retrieval alone will not be enough. The product needs a better evidence representation for multi-session synthesis.
The biggest near-term improvement is probably the two-pass reader: retrieve the top 10 sessions, extract one-line facts from each, synthesize the answer from those compact facts, and judge with fixed templates. That changes the reader’s job from “read five noisy sessions and answer” to “reason over a small evidence table.” For multi-session tasks, that is a different problem.
What This Changes About Brain
Brain was not built for LongMemEval. It was built so an agent could remember my actual work.
That is why the 81.60% result matters to me. It says a local-first, markdown-native, BM25-first memory system can already compete with serious memory products on a hard public benchmark, even before the more sophisticated parts of the stack are turned on.
More importantly, it says the product direction is sane. Brain does not need to make every agent session enormous. It can index the user’s important data once, expose a narrow natural query surface, retrieve cheap evidence slices, and let Claude Code, OpenClaw, and Hermes use that evidence only when they need it.
But the number also prevents overclaiming. Brain is not done. It is not “solved memory.” It is not at 95%. It still struggles where memory becomes synthesis.
That is the right kind of result for a product: strong enough to justify the architecture, specific enough to tell me what to fix next.
The real artifact is not just the score. It is the discipline:
| Discipline | Why it matters |
|---|---|
| Full 500-question runs | Avoids cherry-picking. |
| Separate retrieval and QA metrics | Prevents recall from masquerading as intelligence. |
| Fixed judge templates | Keeps improvement honest. |
| Error-free score only | Makes the number defensible. |
| Per-category breakdowns | Turns the benchmark into a roadmap. |
I started Brain because I wanted Claude Code to stop forgetting my past work.
I benchmarked Brain because the product I want has a harder requirement: agents should remember without wasting my time, wasting my tokens, or pretending to know what they failed to retrieve.
The clean score is 81.60%. The next target is not a prettier blog headline. It is a faster, cheaper, more natural Brain that makes multi-session memory feel like part of the agent’s normal working environment.

Links Worth Following
If you want to inspect the concepts behind this benchmark, these are the links I would start with:
| Topic | Link | Why it matters |
|---|---|---|
| LongMemEval paper | arXiv 2410.10813 | Defines the benchmark and long-term memory task shape. |
| LongMemEval code/data format | GitHub: xiaowu0162/LongMemEval | Shows dataset files, evaluation scripts, and question types. |
| Cleaned LongMemEval data | Hugging Face dataset | The cleaned files behind the run. |
| Supermemory comparison | Supermemory research | Per-category breakdown — the only public apples-to-apples shape comparison. |
| Mastra leaderboard | Observational Memory | The most-cited public LongMemEval scoreboard; aggregates Mastra, Hindsight, Emergence, Supermemory, Zep. |
| QMD | GitHub: tobi/qmd | Local retrieval substrate Brain builds on. |
| MCP | Model Context Protocol | Protocol surface for exposing tools/data to agents. |
| BM25 | Stanford IR book: Okapi BM25 | The lexical ranking baseline that got surprisingly far. |
| HyDE | ACL Anthology: Hypothetical Document Embeddings | Useful background for QMD’s hypothetical-document retrieval mode. |
| Claude Code headless mode | Claude Code -p docs | How the Sonnet reader was driven from the harness. |
| Claude Code hooks | Hooks reference | How everyday Brain ingestion connects back to agent sessions. |